

How You Can Optimize Your Logging Aggregation Costs
Log aggregation systems are awesome. They truly are. Being able to get any log I want from my servers with just a few clicks is not only fun but a huge productivity boost.
I have all my logs in one place. All applications. Each microservice. Every load-balanced instance. The entire infrastructure. Plus, I can search through it with queries. I can extract specific fields from my (structured!) logs and split them into tables. Then, I can graph those data points with a click of a button. But why, oh why, does the cost of logging have to be so expensive?
So much money
If you are using a SaaS offering to aggregate your logs such as Datadog Logging, Logz.io or Splunk Cloud, you are probably paying anywhere from hundreds to hundreds of thousands of dollars per month. If you are managing your own infrastructure, on-prem or in the cloud, computing costs are probably lower, but your TCO (Total Cost of Ownership) is probably even higher. And all of that without even getting into the costs of pipelining the data from your applications to your log aggregation platform. So why are we paying so much money?
Well, we are bringing in a ton of data and want to keep it for a period of time. That’s a lot of storage. We want to be able to run fast queries on that data so we need to use fast storage formats such as SSDs, and we need additional storage capacity for the indices. Ingestion for building those indices and make the data available as fast as possible requires a lot of computing power. Storing some of these indices requires memory, plus processing our queries and sending back the result also demands significant memory and CPU resources.
All in all, we need a lot of expensive storage, plenty of RAM and powerful CPUs to bring the luxury of log aggregation to life. The question remains: what can we do about it?
Reduce Logging Volume
The easiest way to get started is to figure out which logs are taking up the most space (duh!) and then to remove them. Surprisingly enough, the size of logs is a multiplication of log counts and individual log sizes. And so, we need to figure out how many times a log repeats itself (which is fairly easy) and the size of an individual log record.
You can do that in Logstash using this snippet:
Now that you have that log, draw a nice little graph showing the log volume over time:
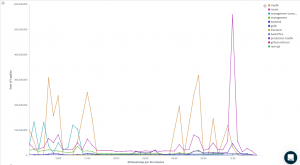
Then start slicing and dicing your data by filters, such as:
- Microservices
- Environments
- Verbosity levels
- Specific log lines
Once you find out which logs are taking up a lot of space, you’ll have to figure out what to do with them.
For logs created by your own applications:
- If the log is very large, you’re probably including large variables (such as buffers and collections) in the record. Try to cut back and only include the parts of the objects you truly care about.
- If the log is happening too often, could it be too detailed? Can you replace it with a log at a higher level of abstraction? Or aggregate the logs by counting or summing within the app?
- If all else fails, or if the log is not important enough, reduce it’s verbosity so that it will not be created in the relevant environments.
For logs created by 3rd party applications check out their logging configuration. Can you define the verbosity? Can you define which events you care about? If all else fails, you can use drop filters in your log processor or log aggregator to remove the excess logs.
Focus on concise logging formats
If you are doing logging right, you are probably using structured logging.
Despite all its advantages, we’ve learned from experience that structured logging has the disadvantage of not only being larger but often including a lot of repetitive metadata. For example, each of our (optimized) log records contains all of this metadata.
Your configuration might be including a lot more metadata, and if you go overboard with data enrichment you might find yourself increasing log sizes by a factor of 10 or more. Take a look at your log metadata and see if you can optimize it.
If you have insignificant or seldom-used fields in your metadata, consider removing them. Just like some of our customers, you may be surprised by the volume saving this can generate. For important metadata fields that you want to keep, make sure they are efficiently represented within the JSON (or whatever format you are using). Try to use the short forms of values, avoid unnecessary padding, and don’t forget to optimize field names. While I’m not advocating for single-character field names, “application-remote-customer-primary-key” may be safely replaced with “customer-key”.
Archive your logs
For day-to-day operations within your group, you probably need to keep logs for a timeframe of anywhere between a few days and a few weeks. While you always want more, older data just tends to be less useful. On the other hand, security, compliance, and regulatory requirements often mandate keeping logs for anywhere between 90 days and 7 years. For a quick comparison, the difference between keeping logs for 14 days and 90 days is a factor of over 6. That’s a huge jump up in our log volume for little to no value.
Don’t use high-cost log aggregation services to keep log backups lying around, just in case. Archive your logs into cold storage services such as Amazon S3 Glacier and load them back if and when you need them. If you are using logs for long-term metrics tracking, well, just don’t. While I won’t go into the various approaches and tools for long-term metrics tracking, you check out this simple guide for generating aggregating metrics from your log data.
Reduce logging FOMO
One of the biggest factors in writing logs is the so-called “logging FOMO”. The fear of being blind to what our software is doing is constantly driving us to add more and more logs. As long as software engineers are pushing for more and more data collection with managers and ops pushing back on costs, we are in a zero-sum game. New, responsive logging tools ease much of that tension by allowing engineers to instantly collect the data they need. Our customers often mention how easy and frictionless obtaining data is without being dependent on organizational approval and technical processes.
When you hit your logging quota, try using some of the aforementioned methods to trim them back down. Applying these tips will do more than just leave more breathing room in your budget. It will improve the verbosity of your logs and optimize your entire logging workflow by allowing you to focus on the data that really matters.
Related posts



