

Lessons Learned When Building A Kubernetes Operator
As we see more customers adopting Rookout for debugging cloud-native applications, we are not surprised to learn that a significant number of them work in a microservice environment. In the most common case among these customers, each service has its own code repository maintained by the team who develops the service. And although deploying Rookout in a single microservice or application is as easy as adding a single line of code, we learned from our customers that managing Rookout’s configuration across so many repositories was shaping up to be an inconvenience.

So we decided to take a step back and think up ways to make life even sweeter for our customers, and to make managing a complex Rookout setup as easy as it should be. We wanted to make it possible to manage the setup in a declarative manner, as you would expect it to be done in a Kubernetes environment. And then the figurative lightbulb went off above our heads. We knew that all those services get deployed on the same Kubernetes cluster, so what if we could manage Rookout’s configuration from the cluster itself? And thus, the concept of implementing a Kubernetes Operator was born.
So, what’s an Operator?
An Operator is a Kubernetes cluster core building block that is responsible for maintaining cluster resources such as deployments, pods, containers, or any other such resource that is able to be configured via kubernetes YAML objects and kubectl.
Whenever a developer runs `kubectl apply -f deployment.yaml`, there is always at least one, if not more, Operators that get notified about the changes that were requested and take care of them for you. For example when you request an SSL certificate in your deployment YAML file, there is an Operator in the cluster that listens to certificate requests, generates them, and then injects them to the relevant pods.
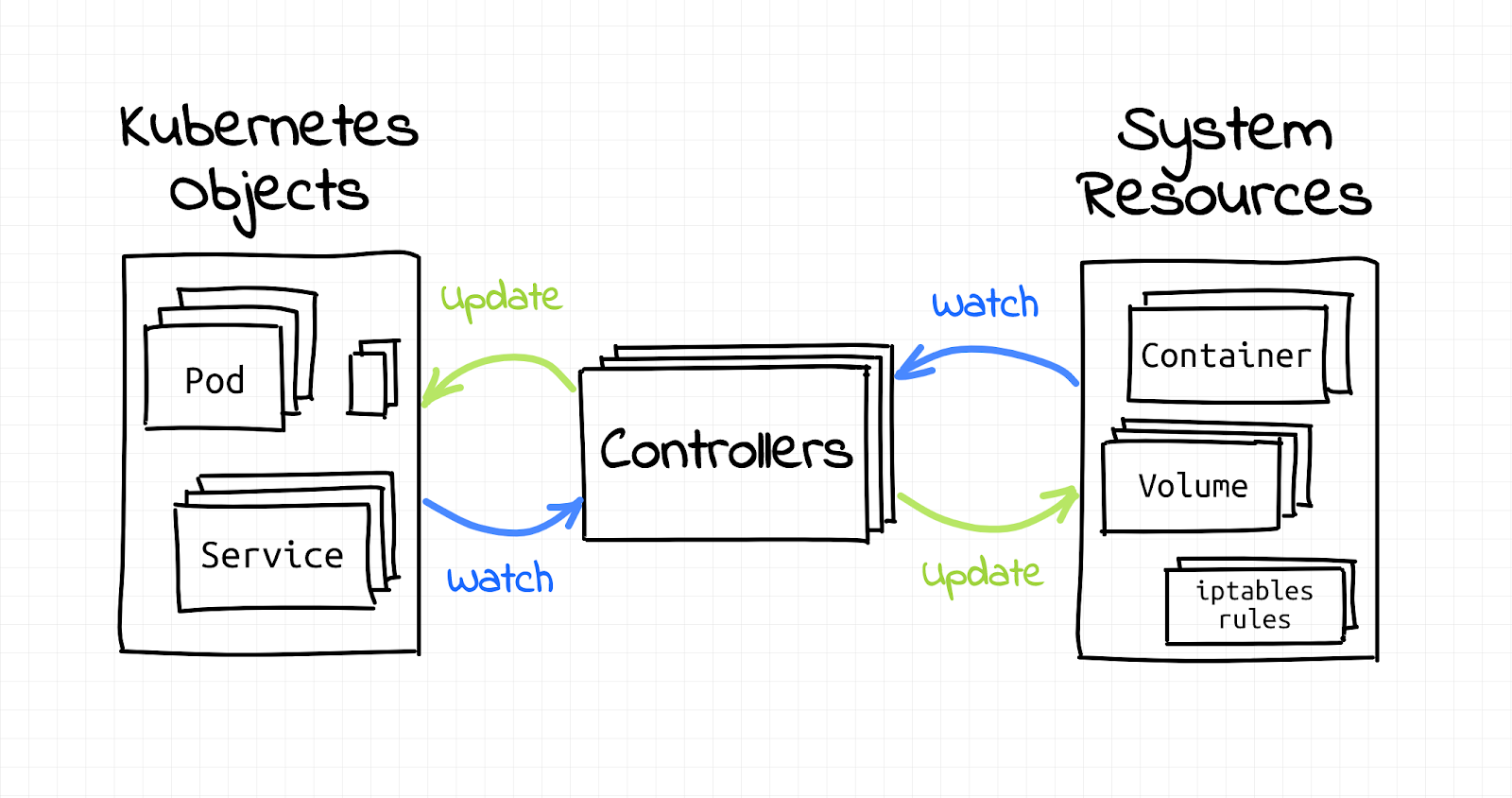
[Image source: Ivan’s blog post]
Operators are implemented as pods that run on their dedicated namespace and they have special permissions to apply changes on resources on other namespaces. Each Operator needs to be registered to at least one resource that it takes care of and asks for its specific permissions in order to manage it (but we’ll talk about that more further on, don’t worry!).
Why did we implement our own Operator?
Before we created the Rookout Operator, our deployment process in a Kubernetes cluster required updating each app that the developer would want to debug with Rookout. The modification included embedding Rookout by changing the container image or by modifying the deployment yamls of the app.
This modification process could be quite onerous for dev teams who have hundreds or thousands of apps in their organization. This would create an unfortunate situation for the DevOps engineer or the application developer who would need to go over each service and change its code in order to load Rookout with their custom labels. Said labels are required to allow developers and DevOps engineers to identify their apps on Rookout’s Web IDE, and before we created the Operator, they would need to repeat this process over again every time they would want to change those labels.
Implementing an Operator allowed us to load the Rookout SDK in a fully transparent way. Even better, we were able to do this with no code changes to the original application or its deployment yaml.
How does the Rookout Operator work?
The Rookout Operator is installed via helm or kubectl and its pod gets created in its own namespace.
It then registers itself to the following resources :
- Deployment – so it can apply the required changes on it to install the Rookout SDK
- Rookout Configuration – for configuring where and how to install Rookout
Next, the Operator waits for Rookout Configuration Resource to be added so it will have the configuration for deploying the Rookout SDK. Rookout configuration contains a list of matchers composed by a combination of deployment name, container name, and labels. Once the configuration is set, the Rookout Operator can start to patch deployment resources.
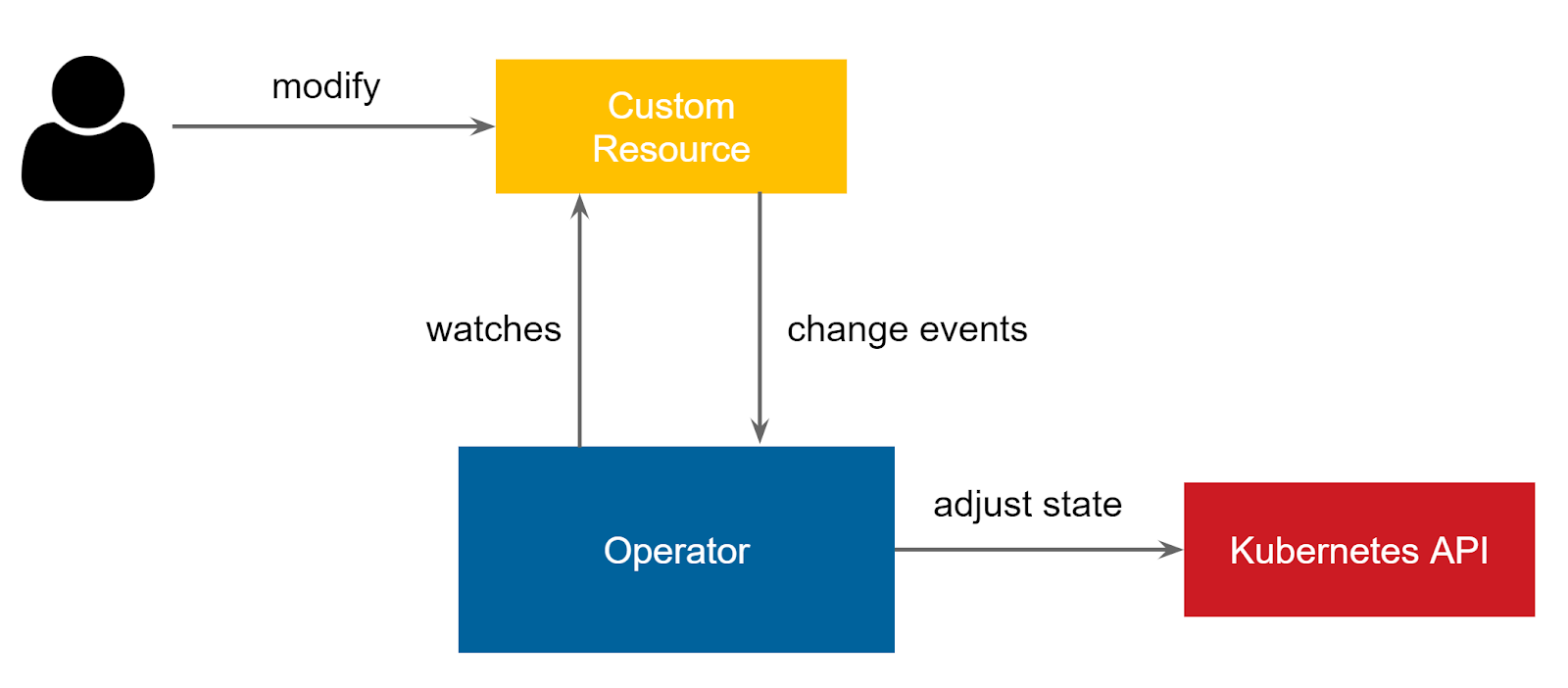
[Image source: openshift blog]
Every time a deployment is created, updated, or deleted, the Rookout Operator gets notified and has the ability to modify it. The modification is done the same way as we do it via `kubectl apply`, except that the Operator uses the Kubernetes API client directly (as a Go package) and does not depend on the kubectl binary.
How do we patch a deployment?
Initially, we add an init container that places Rookout SDK artifacts in a shared volume which is accessible to the other containers in the same pod.
Then, we add an environment variable to the relevant containers in the deployment which tells their JVM to load Rookout agent from the shared volume before the main java app starts.
Rookout patches deployment resources using the kubernetes client for Golang. You can take a look at our patching code in our public operator repo. In order to be able to patch deployments the operator needs to have the deployment:patch permission. We add this permission with a special annotation in the code.
This annotation tells the build process to generate the following RBAC yaml for the operator, which contains all the operator required permissions, and specifically deployments:PATCH for applying Rookout on requested deployments.
Let’s talk security
Operators are very powerful, as they have cluster wide permissions. When implementing an Operator, it’s necessary to pay a lot of attention – and ask permissions – for only the required resources and the required actions for those resources.
For example, if our operator asks for access to be notified when changes are made in deployment resources and for permission to then patch it, it will also ask to be notified of changes to Rookout Configuration resource.
That’s it – no less, no more.
Customize your Kubernetes cluster
The implementation of Kubernetes Operators opens the gate to the world of Kubernetes internals. It might sound a bit scary at first, but once you get used to the concepts you’ll realize how much power your developers will have. And the best part? It’s all by simply adding your custom logic to a Kubernetes cluster and having the ability to share your own awesome logic with the entire community.

You can create operators that enforce custom security policies in your cluster and add support to new resource types like SQL/Document databases, which will behave as native Kubernetes components and will be configured in the same yamls you already use for your deployments. Sounds too good to be true, right? It’s not.
I hope this tutorial inspired you to start work on your own Kubernetes Operator and join this amazing ecosystem.
Related posts



