

Live Debugging vs. Remote Debugging: Key Differences and Limitations
As you could probably guess, we discuss debugging a lot at Rookout. We tackle many methods and strategies throughout all our blogs and resources. However, it only recently occurred to us that we don’t have a direct face-off of the two major methods of modern debugs: live debugging vs. remote debugging.
At first glance, this might sound like semantics, but the two terms have come to embody specific methods and protocols. Both are powerful, but there is some fine print to look at also.
Challenges to Debugging in the Cloud
Cloud-native apps are more distributed than classic programs or apps using monolithic architectures. This has to do with 1) the fact that by definition cloud-native apps live on other servers, and 2) they are probably based on microservices architectures.
To make a long story short, microservices make monitoring and troubleshooting more difficult because they disperse the individual services of an application across multiple locations: containers, pods, nodes, servers, and possibly multiple cloud-hosting providers.
Remote debugging specifically – and cloud-native observability generally – requires more sophisticated strategies to properly identify and then address errors.
Decentralized apps are harder to debug for a few reasons:
- Replicating the conditions that produced a bug is difficult since microservices are distributed so widely within an application architecture.
- The additional substructures – containers, instances, pods, nodes, etc. – produce their own logs, metrics, and telemetry data. Taken all together, there is a lot more noise in observability data.
What is Remote Debugging?
Remote debugging describes the troubleshooting or debugging of code that is on a separate machine, usually hosted in the cloud. Cloud servers are ubiquitous in modern development, so the simple definition of remote debugging carries with it some essential connotations innate to present-day cloud development.
Because of the wide net that a remote debugging process must cast, it’s best to focus on using either 1) tools integrated with or part of major cloud providers, or 2) to access your code with IDE to launch a remote debug session.
Remote Debugging with VSCode and Intellij
VSCode remote debugging is built-in for Node.js (including TypeScript and vanilla JavaScript). Remote debugging resources for other languages depend on plugins in the VSCode Marketplace for a given language, but their quality can vary from one to the other.
You can configure Node.js remote debugging with VSCode’s Remote Development extension, or via the Node.js debugger:
{
"type": "node",
"request": "attach",
"name": "Attach to remote",
"address": "10.222.233.244",
"port": 9229
}You would use the LOADED SCRIPTS feature to select a pre-loaded piece of code or load a new one. You then set breakpoints in a read-only editor. Y
ou can also set the debugger to restart once code edits have been made. You can use the Restart Frame to restart a selection of code where you make any changes.
Intellij remote debugging is more restrictive. Any app you run through Intellij must follow the default compiler setting to work at full capacity.
Additionally, according to JetBrains’ documentation, decompiled code debugging is more complicated with Intellij. You must add additional configurations to run the debugger, namely by selecting the Remote JVM Debug option under Add New Configuration.
Intellij’s emulated method breakpoints are considered superior to other varieties in Intellij, such as line breakpoints.
However, and this can be a major drawback to using Intellij in this situation, JetBrains recommends disabling emulated method breakpoints during remote debugging. Latency is an issue when using this approach, so simpler breakpoints are recommended.
Remote Debugging Cons
As a method, remote debugging falls short in several ways.
1. Admin-Only Access
Firstly, you will need admin access to the relevant server to actually apply the proper remote debugging settings – this limits who can initiate a debug session, a critical weakness should something happen in production.
That admin access issue exists in part because of the next reason: data exposure.
2. Data Exposure
Data exposure is a risk with remote debug sessions. The way traffic goes in and out between the server and your environment, plus the way data is requested, can reveal tokens and passwords to dev teams during the debug.
Add to that that internal application traffic, say between microservices or in a multithreaded environment, will complicate rooting out the cause.
3. Microservice-Based Architecture
Independent services will have different configurations relative to their code, logging practices, where they fit in the structure of the entire application, and more.
Keeping track of each and every single method of debugging is difficult, pressing on dev teams’ own bandwidth.
4. Latency
Latency is a tremendous wildcard. The strength of your connection, unaccountable factors on either side of the connection, and even your location relative to the cloud server can slow down the debug process, even leading to timeouts that further delay solving problems.
In fact, IntelliJ recommends not using ᴍᴇᴛʜᴏᴅ ʙʀᴇᴀᴋᴘᴏɪɴᴛꜱ – of all things – during remote debugs, essentially kneecapping the whole process. Other advanced features will also struggle to reach peak efficiency.
5. Kubernetes
For containers, remote Kubernetes debugging is a nightmare, to put it lightly. Even in production, where it will likely be impossible, you will need to:
- Change your Dockerfile,
- Rebuild the Docker image
- Redeploy that rebuilt image, and finally
- Repeat again and again
It’s just not efficient. If you find yourself going through this runaround, it’s definitely a shot to your time and resources. Additionally, since remote debugging can be a premium feature with many IDEs, it’s also a drain financially.
6. Serverless
Serverless setups theoretically should be more optimal for dealing with things like latency and architecture, but practically speaking it leaves something to be desired. Debugging by individual lines is sometimes unavailable.
There can still be too many kinds of microservice configurations to debug consistently, and proper permissions are still a hurdle. Latency is still an issue, and if you have a distributed team, the time to debugging will vary depending on which servers your ‘serverless’ functions actually reside around the world.
What is Live Debugging?
Live debugging has the advantage of having cloud-native needs incorporated by design. It provides logs, metrics, and distributed tracing data as part of a more holistic debugging process that uses more dynamic instrumentation to switch between log lines and to collect snapshots. It uses bytecode manipulation to run with the application so the app doesn’t have to redeploy with every debug.
Related to but more nuanced than remote debugging, live debugging parallels movements like DevOps: the tasks of development and operations overlap and dovetail.
Just like certain tasks can’t be restricted to pre-production, so too debugging must also happen in production, not just staging and development.
Debugging running code raises the need to ensure the correct version of code is being debugged, fetching your running source code to take a snapshot in the correct context with the relevant conditions.
This all takes a balance of caution and agility or speed to hone in on and remedy bugs as soon as possible immediately.
Version Visibility
In order to query the code, a live debugger has to simultaneously have the most up-to-date version of the code while not allowing the debug process to make permanent changes while it runs in production.
Live debuggers should be able to automatically load a copy of your source code’s repo while 1) not reading the source code, 2) not importing your source code, and 3) not accessing private data.
Security
Live debugging inherently must take extra care of source code as a core tenet.
The best example for live debugging comes from Rookout. Rookout loads source code either locally or from a source control management service (e.g. GitHub, Gitlab, Bitbucket, etc.), directly to your browser.
That means with a service like Rookout, your source code 1) never goes through Rookout’s servers, and 2) cannot be changed. Rookout only observes the state of an application and cannot execute code.
Rookout’s live debugger accesses apps through an encrypted TLS connection and with outbound communication, in line with industry best practices. That contrasts with remote debugging, which uses inbound connections that exposes applications to security risks. In addition,
For what data does get collected, Rookout comes with advanced redaction capabilities to further minimize PII exposure. That data is also under strict, access-controlled storage for less than a week, requiring a unique token to access.
Non-Breaking Breakpoints
Live debugging fetches source code, but does not have direct editing access. That is because of Rookout can use its Auto Loader to produce an up-to-date version. This essentially creates a copy of the very latest version of source code, which can be debugged using non-breaking breakpoints.
Non-breaking breakpoints do not require ‘breaking’ running code – devs don’t have to stopping production-live applications. There is no need to edit the code to add more log lines, eliminating the need for restarts or reloads.
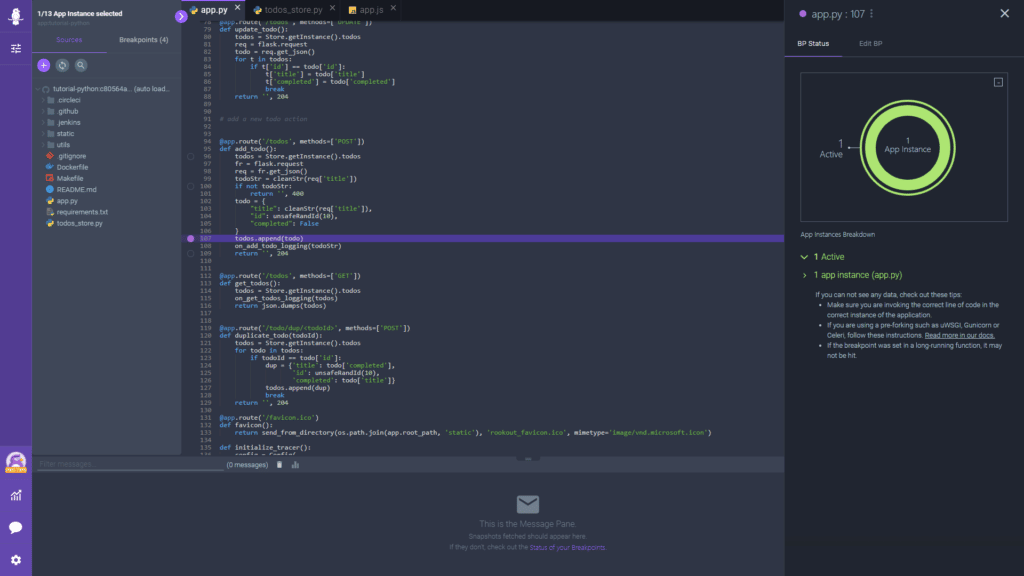
In tune, Rookout’s breakpoints are non-breaking breakpoints – they don’t stop running code, or even require that you add more code in order to have more log lines. They also circumvent remote debugging’s restrictions on stronger kinds of breakpoints.
| Remote Debugging | Live Debugging | |
|---|---|---|
| Breakpoints and Latency | Breakpoints are hampered by issues of latency in remote debugging setups. Intellij considers it best practice not to use emulated method breakpoints during remote setups. Even when a remote debug doesn’t time out, the duration of the debug is unpredictable. | Non-breaking breakpoints act on a copy of the latest version of source code, so it has local access to the code sections being debugged. Live debuggers fetch the code, but don’t run it. Latency is eliminated from the equation here, as the debug only begins after fetching the code. |
| Security | Giving admin permissions to too many team members is just one vulnerability. Direct access by a debugger server to source code further risks exposing personal data | Direct access to source code is impossible with live debugging. Source code is never read by or stored on Rookout servers. |
| Limited Human Resources | You must have administrator-level access to conduct remote debug sessions. That obviously limits your whole team’s flexibility to get things done. Opening up that level of access is easy, but also a security issue. | Live debugging does not strictly require admin access. Additional security measures also allow the leeway to permit more developers to run live debug sessions themselves. |
| Version Visibility | There is a lot of room for error here. It’s easy to select the wrong version of source code for your debug. | Auto loading a copy of the current version of source code, without allowing change-capable access, protects the code from unwanted changes. The additional benefit of non-breaking breakpoints also closes off any need to make changes specific to debug sessions, anyway. |
Live Debugging vs. Remote Debugging: Connecting the Whole Stack
Your live debugger should be able to link up with your code repositories to import code as well as to export debug data. That’s where a tool like Rookout will come in handy.
First, it syncs with source code in git repos, and allows automatic loading to make sure the correct version is being debugged when a debug session is started.
Remote debugging grew by necessity to meet the unique needs of microservice architectures that organically developed out of new cloud-native services. Live debugging is an evolutionary step for cloud-native debugging, incorporating the practical abilities to debug Kubernetes, serverless deployments, and overcoming concerns about latency and security with microservices in ways that remote debugging cannot.
To get a true feel for live debugging, try out the Rookout Live Debugger for free!
Related posts



