

The Benefits of Bringing Together Debugging and Distributed Tracing Tools
The rise in digital transformation over the past few years means that more and more companies are adopting cloud native technologies. While these distributed architectures provide scalability and agility, they also increase complexity. As Arnal Dayaratna, research director in software development for IDC, writes, “One of the challenges faced by contemporary developers is the task of understanding applications that they may not have even developed or used [whether it be third-party, open source, or code written by a colleague].”
Traditional debugging methods, such as step-by-step debugging, are practically impossible to use in cloud native environments. There is never a single server to connect to and debug, since the environments are dynamic, and containers, pods and serverless functions spin up and down on the fly.
Developers often fall back to log-based debugging, which brings its own set of challenges in cloud native environments. Logging costs become significant, as does performance impact. And it means having to add a line of logging code, wait for a new release and waste precious development time while delaying issue resolution.
These challenges have given rise to distributed tracing, which has taken over the industry as the de facto method for monitoring and troubleshooting cloud-based applications. Tracing, a complement to logging and monitoring, is now considered one of the foundations of observability. It’s a relatively new industry trend that emphasizes the ability to view the internal state of the application in real time. The most prominent distributed tracing implementation is the OpenTelemetry project, the second most active Cloud Native Computing Foundation (CNCF) project behind only Kubernetes.
OpenTelemetry and the tracing tools that implement it — such as Jaeger, Zipkin and Lightstep — offer developers the ability to see the internal relations between different cloud-based microservices and provides invaluable context when trying to troubleshoot a complex and dynamic environment. The ability to combine tracing information with code-level, context-specific debug data gives developers an even deeper insight into application behavior, taking observability into its next evolutionary step: understandability. This is the ability to not just view the internal state of the application, but also to fully understand its structure and function.
Within modern debuggers, developers can place what are called “non-breaking breakpoints” into an application, to collect data such as local variables and various tags. But the ideal workflow would also collect tracing data at these specific breakpoints, providing rich context for more rapid troubleshooting that include observability data like distributed traces, spans and logs. Here at Rookout, we’ve integrated with OpenTelemetry to create a Tracing Timeline that visualizes these typically disparate data sets side by side:
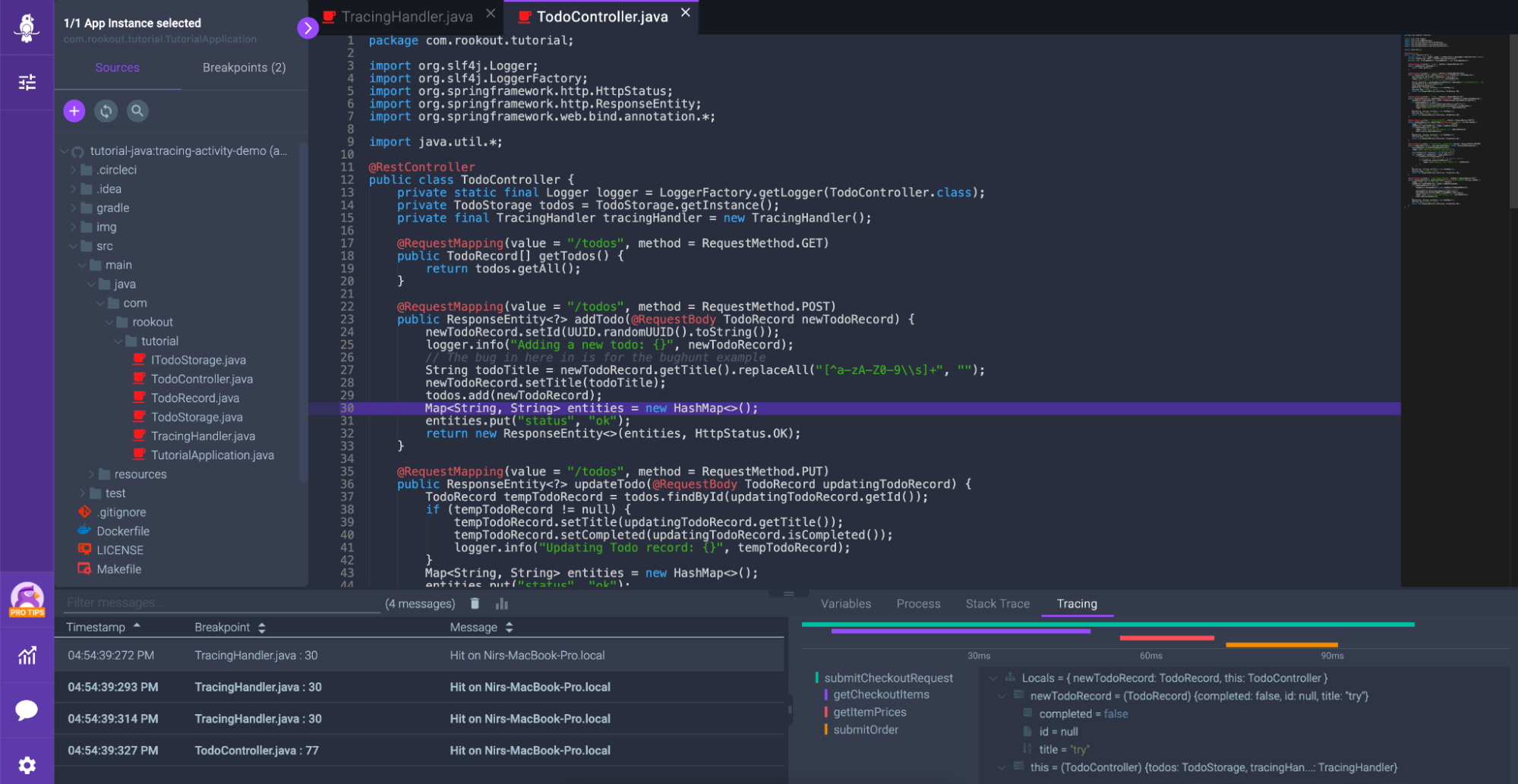
Paval Fux, a senior director of engineering at GrubHub, writes, “Traces are important telemetry when trying to understand where something went wrong, but it’s also time-consuming to switch contexts back and forth between the observability tool and the debugger. Having the ability to view debug snapshots and tracing data side by side gives me the capability to see the full picture and makes it easier for me to get to the root cause faster.”
The new blend of modern, non-breaking debuggers with distributed tracing must become prevalent if we are to solve the increasing challenges of cloud-native applications like complexity and dependency on third-party code. Log-based debugging and traditional step-by-step debuggers will only take us so far. We look forward to a future where the software industry enhances observability into understandability, giving us a deeper insight into the behavior of our applications in ever-evolving technologies.
This article was originally published on TheNewStack
Related posts



