

Configuring & Debugging a Multibranch Kubernetes-Native Pipeline with Argo
We always want to use the best of the best when it comes to Kubernetes tooling. We keep up with the latest projects, download them when ready to try them out, and see where they could fit in our development work here at Rookout. As part of our migration to Kubernetes-native tools, our most important goal is to make it seamless and smooth so our developers will stay agile, fast, and happy. For some of that migration, we’ve faced some challenges, particularly with pipelines.
Our developers maintain their own pipelines just by the code repo, using Jenkinsfile or GitHub Actions workflows. This allows them to maintain their pipeline in a sandbox environment without influencing their team pipeline. Only after making sure everything is right, the pipeline can update within the main branch by pull request.
This multibranch pipeline feature is crucial for keeping our teams agile and fast. Therefore as a DevOps engineer at Rookout, my team and I have reviewed several tools to migrate to k8s native CI/CD pipelines. and, as a Kubernetes enthusiast, I am looking for the most powerful k8s-native tools to get the best performance out of it.
One tool that has made a big impression on us is Argo. Well, two tools really: Argo Workflows and Argo Events. Together, they suit our needs as an advanced CI tool, giving us more freedom with custom configuration and logic.
This tutorial will cover building out and configuring and then performing a debug on a Kubernetes-native multibranch pipeline using Argo. Over the course of the walkthrough, we’ll use the Rookout Live Debugger to debug ArgoEvents.
Argo’s Benefits
We’re not only using it for pipelines but other automated processes, such as our data platform ETLs. By adopting these tools we have significantly sped up our build process. Argo gives us:
- Parallel testing
- On-demand temporary environments of our microservices applications, and
- A much faster build process
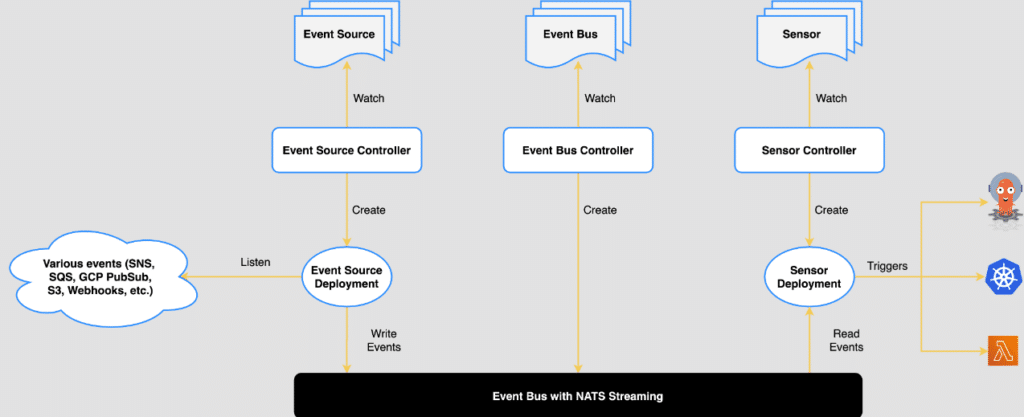
We now manage each step of the build process with version control and, of course, in GitOps with ArgoCD.
ArgoCD also uses CRDs (Custom Resource Definition), Kubernetes Custom Resource Definitions that record the desired state of and allow configuration of ArgoCD clusters.
Management of Argo Workflow Template CRDs takes place in a centralized repo, making it easy to use standard steps like kaniko build parameterized steps or GitHub action steps.
However, if our team wants to add a new step in a sandbox environment just “near their code” as they are used to doing, things can get messy.
Multibranch Pipelines
For that problem, I thought about how I could give our dev teams that multi-branch pipeline that they’re used to. My solution is a lean YAML interface inside the repo that configures their pipeline.
This lean format is much more developer-first – e.g., devs can focus on the logic itself and fear configuring long YAML files.
- name: main
steps:
- - name: step1
container:
image: alpine
command: [echo]
args:
- "injection test"This lean configuration is then passed as JSON inside a POST HTTP request and with GitHub Actions – for each push – in any branch to our Argo Events EventSource. Metadata is also passed for labeling, such as committer identity, branch name, etc.
Configuring the Multibranch Pipeline
Now we can use the pipeline configuration as a parameter inside Workflows that a Sensor can create for us (with a k8s trigger) – we just need to parameterize it right. An example is provided here:
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: sensorexample
namespace: argocd
labels:
k8s-app: argo-workflows
spec:
template:
serviceAccountName: argo-wf
dependencies:
- name: multi-branch-pipeline
eventSourceName: event-source-example
eventName: multibranchpipeline
triggers:
- template:
name: multi-branch-pipepline
k8s:
operation: create
source:
resource:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: multi-branch-pipepline-
spec:
entrypoint: main
serviceAccountName: argo-wf
templates:
<STEPS INJECTED HERE>
parameters:
- src:
dependencyName: multi-branch-pipeline
dataKey: body.injected
dest: spec.templatesAnd here is an example of the JSON body that will be passed:
{
"injected": [
{
"name": "main",
"steps": [
[
{
"name": "step1",
"container": null,
"image": "alpine",
"command": [
"echo"
],
"args": [
"injection test"
]
}
]
]
}
]
}
After creating a new Workflow CRD inside the cluster, the ArgoWorkflows controller will handle the heavy lifting by consuming the Workflow CRD and then running those multi-pod pipelines.
That’s the true power of microservice architecture and controllers!
A Kubernetes-Native Debug Process Using Rookout
The only problem with the above approach is that ArgoEvents doesn’t yet support the injection of blocks using parameters.
In fact, there is a bug in ArgoEvents itself. We can’t <em>"unmarshall" </em>the workflow instance spec.
When the Workflows CRD returns “cannot unmarshall spec: cannot restore struct from: string”, it means that the block parameter is serialized into a string and can’t be injected as JSON.
But hey, this is open source! We can debug it and contribute back to the growing Kubernetes-native community.
To accomplish that fast, I have injected the Rookout rook (agent) into the sensor section of ArgoEvents so that we can debug the sensor that we’re creating. I’ve also injected ENV parameters to the sensor container like Rookout’s token and other ENVs as shown below in order to configure it right.
sensors/cmd/start.go:
Import (
...
rook "github.com/Rookout/GoSDK"
)
func Start() {
err := rook.Start(rook.RookOptions{Labels: map[string]string{"app": "argo-sensor"}})
if err != nil {
fmt.Println(err)
}
...
controllers/sensor/resource.go:
func buildDeployment(args *AdaptorArgs, eventBus *eventbusv1alpha1.EventBus) (*appv1.Deployment, error)
...
envVars := []corev1.EnvVar{
...
{
Name: "ROOKOUT_TOKEN",
Value: "...",
},
{
Name: "ROOKOUT_REMOTE_ORIGIN",
Value: "https://github.com/argoproj/argo-events.git",
},
{
Name: "ROOKOUT_COMMIT",
Value: "master",
},
{
Name: "DEBUG_LOG",
Value: "true",
},
}
}
Also for source fetching, I used Rookout’s Explorer feature that allows me to grab the source code locally, and was very useful for self-built images that I have tested.
After injecting our Rookout agent inside the code, I’ve built it out and switched the container image of the sensor for a new version of the image that includes the agent.
With everything in place, we can now access and debug Kubernetes-native code inside the Rookout Web-IDE. We place breakpoints and launch the debug process. The Rookout Live Debugger uses non-breaking breakpoints, which allows you to debug without stopping your code or relaunching your container.
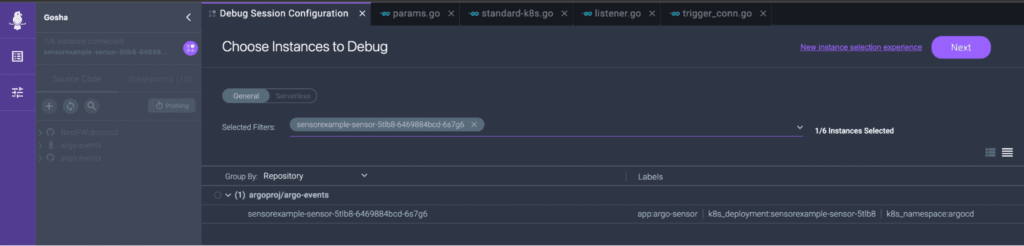
After a quick look I have found what was the problem. The function ApplyParams in the sensors/triggers/params.go file. This file injects parameters to the JSON using the SJSON package with the SetBytes function. This function was getting an incorrect value – in that *value that contained escape characters – leaving the value as a string. This was breaking the injection in the destination field.
Actual state:
"{\"image\":\"docker/whalesay:latest\",\"command\":[\"cowsay\"],\"args\":[\"injected\"]}"Desired state:
"{"image":"docker/whalesay:latest","command":["cowsay"],"args":["injected"]}"Now, we have two ways to solve this problem.
Option 1: We could fix *value so the string will be serialized correctly without the escape characters.
Option 2: We can go with the flow and find a way to use this serialized JSON.
Plan A: Fixing the Value
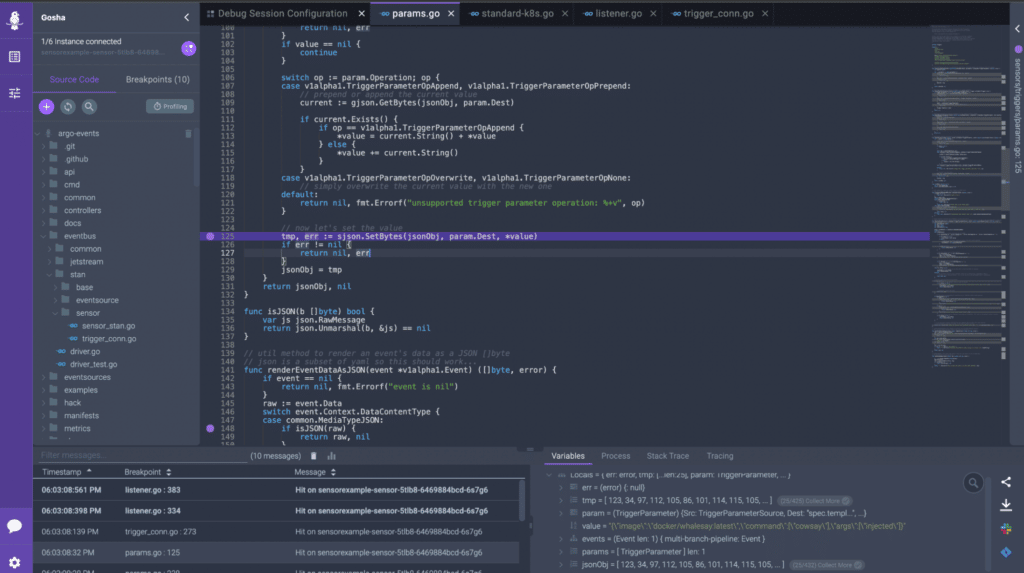
I have followed *value and tracked its creation to the getValueByKey function called by ResolveParamValue. But the problem wasn’t from here.
To make a long story short, the root cause is the serialization of the payload’s data with the CloudEvents SDK-Go V2 library that is used in the convertEvent function in trigger/listener.go. Rookout’s Stack Trace feature made it easy for me to find it fast.
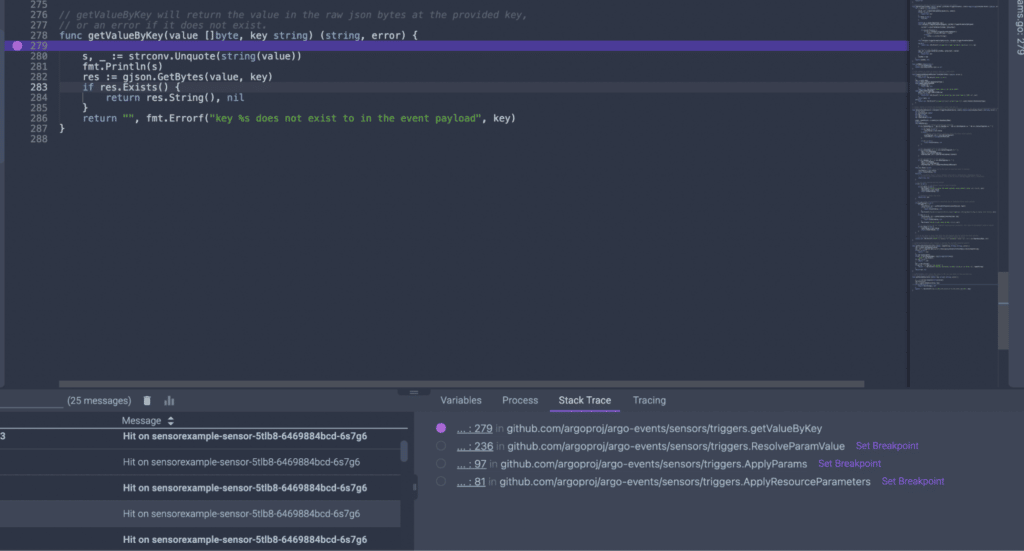
Although fixing the library is very tempting, I am not sure that we should fix it there. Besides, I don’t know what impact there will be on other functions.
Because of all that, I’m going to follow the second approach.
Plan B: Serialized JSON
I will try to use the same backslash string with a different approach. I’ve found that casting it to []byte and using the SetRawBytes function of SJSON works just fine. Therefore, this will be my fix. I have tested it and it works.
sensors/triggers/param.go:
func ApplyParams(jsonObj []byte, params []v1alpha1.TriggerParameter, events map[string]*v1alpha1.Event) ([]byte, error) {
...
// now let's set the value
tmp, err := sjson.SetRawBytes(jsonObj, param.Dest, []byte(*value))
if err != nil {
return nil, err
}
jsonObj = tmp
}
return jsonObj, nil
}
An issue has been opened on GitHub as well as a PR.
ArgoCD’s ApplicationSet
Let’s consider another approach: leveraging ArgoCD’s ApplicationSet with the generator SCM provider. It can scan all the repos, extract that lean YAML configuration, and then inject it into a generic Argo Workflow. The Workflow is templated using a Helm chart.
Firstly, I have to create a Workflow Helm chart. It should have the branch name, SHA of the commit, and so on. Also, the name has been parameterized to force the ArgoCD application to create a new CRD instead of updating the old one. Here is a modest example of this POC:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: {{ template "workflow.fullname" . }}
labels:
{{ toYaml .Values.labels | nindent 4 }}
spec:
entrypoint: whalesay
arguments:
parameters:
{{- with .Values.parameters }}
{{- toYaml . | nindent 6 }}
{{- end }}
serviceAccountName: argo-wf
templates:
{{- with .Values.templates }}
{{- toYaml . | nindent 4 }}
{{- end }}And the values.yaml file:
fullname:
labels:
sha:
branch:
parameters:
templates:Of course, a helper is used to name the Workflow properly.
Next, we’ll create one ApplicationSet CRD to find the lean YAML configuration within the target repos of our organization’s repositories.
Then, we’ll inject them into the Workflow Helm chart as a values file.
A generator provides us a useful parametrization of the generated ArgoCD Application. That generator will inject the commit SHA and branch name into the Helm chart (labels). I also used a filter to skip all the repos that don’t contain a workflow/ci.yaml file:
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: mypipelines
spec:
generators:
- scmProvider:
filters:
- pathsExist: [workflow/ci.yaml]
github:
organization: rookout
allBranches: true
tokenRef:
secretName: github-token
key: token
template:
metadata:
name: '{{ repository }}-{{ branch }}'
spec:
source:
repoURL: <URL OF THE HELM CHART>
targetRevision: <CHART VERSION>
chart: workflow-chart
helm:
values: |
labels:
sha: '{{ sha }}'
branch: '{{ branch }}'
valueFiles:
- ci.yaml
project: default
destination:
server: https://kubernetes.default.svc
namespace: argocd
Now, I only need one last, small modification to the lean YAML formatting. The file should be placed in the /workflow folder in the repo and called ci.yaml. Here is an example of a ci.yaml file:
fullname: multi-branch-pipeline
templates:
- name: whalesay
container:
image: alpine
command: [echo]
args:
- "injection test"Great! We now have a multi-branch pipeline solution for our dev teams! There are several problems with this solution, though.


Firstly, there is a delay in pushing a new commit to the building, thanks to a ArgoCD re-consolidations delay. We can solve that by refreshing the application using GitHub actions and the ArgoCD CLI.
Secondly, we lose the ‘build history’ when we overwrite the original CRD. So it’s not the best option, but an ApplicationSet like CRD for Workflows could still be useful.
Conclusion
I have demonstrated how to implement and debug a Kubernetes-native multibranch pipeline using an Argo Events Sensor by injection of a lean YAML configuration from microservice’s repo. Argo didn’t support this implementation, so a we needed to make a short contribution, as well as a debug session using Rookout. Thanks to the Rookout Live Debugger and its non-breaking breakpoints, it was fast and easy to debug the Argo sensor with real-time data.
This is just a sample of how Rookout can debug Kubernetes deployments, including multiple instances at once and identifying problem clusters. Rookout doesn’t require additional configuration for Kubernetes clusters, as Rookout is configured only at build time. For more about Rookout and Kubernetes, try out Rookout for free!
Related posts



