

Fantastic Bugs and How to Resolve Them Ep2: Race Conditions
Come, come sit! Let your weary legs rest, the journey can wait, fellow developer. Have you had a second breakfast yet? You really should have one, but you must be sure you finish your first breakfast, first; Otherwise, there can be quite a race condition in your stomach.

But don’t worry fellow code-traverser, you’re in good company. I can teach you every secret of the trade regarding those pesky bastards. Starting from the very basics, through how to intuitively identify them, and finally, the best practices of how to resolve them.
What are race conditions?
What are race conditions you ask? Well, let me tell you. A race condition is a scenario where two or more flows take place concurrently, affecting one another in an unplanned manner and often manifesting as a bug. Race conditions are the most natural and most common bugs to be found in asynchronous systems (e.g. multi-process, multi-threaded, multiple microservices).
Race conditions are often encountered in the wild. A classic example used to be found in some old Coca-Cola vending machines, where a customer could get two cans for the price of one. The machine would release a soda can just a fraction of a second before it decreased the amount of money saved. Then, a second click on the “buy a can” button would pass since the check for “is there enough money for another can?” would succeed in the time between the approval of the first can and the payment subtraction.
Let’s look at how the code for a vending machine like that might look like using this React JS example:

Try it yourself, put in $1 and try and see how many cans you can get for it.
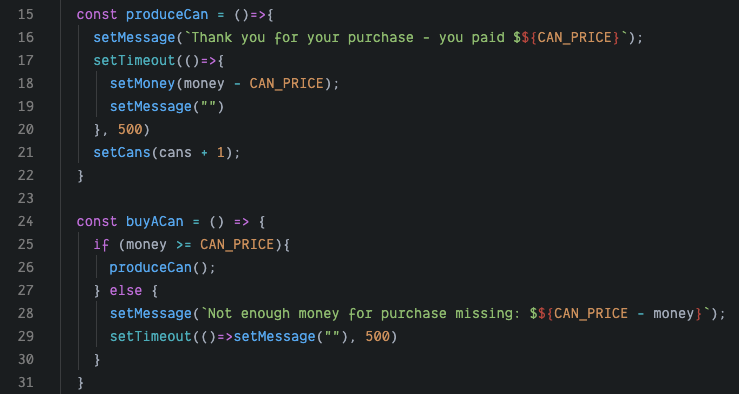
At first glance, the code seems ok. When the user buys a can (via the buyACan function) the money counter is checked for sufficient funds, and only then does the machine continue to produceACan.
Things in this code get tricky when setTimeout is introduced. This function asynchronously executes the code it is given, after the set time (in this case 500 milliseconds). One can imagine a developer adding these to the code to enable a flashing message feature, displaying text for a brief moment while the machine is working. This simple and seemingly cosmetic change creates a bug that ruins the most basic functionality of the machine.
In the 500 milliseconds between the call to the setTimeout which will update the money-count via setMoney, setCans is called once – outputting one can. So far so good. But now, when the user clicks the button again, the flow repeats and since setMoney hasn’t been called yet, the condition passes again and another can is released. Now that’s not good for business.
The example above is, of course, a simple one. It can be simplified even further — the bug is resolved by moving the call to setCans into the setTimeout callback — and yet it is still easy to miss. Real-life race condition bugs are often far more complex and frequently involve multiple moving parts, each adding more obscurity to the whereabouts of the bug.
Intuiting race conditions
Race conditions can indeed be tricky to spot and combat, but an experienced developer can recognize a race condition miles away. The secret is not to look for certainty but to notice the facts pointing to a race condition as the likely cause, and then hone in on it. As you probably already know – the treasure intuition to spot race conditions was inside you all along!

Here are a few rules of thumb to help you intuitively realize a bug you’re working on is likely a race condition.
Sporadic
The bug is sporadic, i.e. it doesn’t appear every time the code runs or its side effects keep on changing. Being sporadic is an attribute race conditions share with Heisenbugs (see Fantastic bugs and how to resolve them ep1: Heisenbugs). In fact, race conditions might be Heisenbugs as well. In fact, a large percentage of Heisenbugs are race conditions or have a race condition aspect to them.
Performance dependent
The bug appears more/less often due to resource utilization (CPU, network, disk). As their name hints, race conditions are all about speed and conflicts in time between two or more async components. As a result, things affecting performance and execution speed will affect the race condition.
Asynchronous nature
An async flow is a prerequisite for a race condition. If the code has a high dependency on asynchronous components, the likelihood of a bug being a race condition increases. Common design patterns that are indicative of race condition likelihood include Microservices, Worker threads, async-queues, readers/writer locks, spinlocks, promises, timers, pub-sub.
First times
Implementing async flows well can be challenging even for experienced developers. Code written by devs implementing async flows for the first time should be suspected to contain race conditions. These may include networking, and basic threading/multi-processing code, on top of the design patterns listed above. Git blame, ‘git ask’ “is this your first time?”, ‘git forgive’ the young fool.
Time-dependent
The bug is time-dependent, e.g. happens a certain amount of time into program execution. Under similar constraints, race conditions have a tendency to repeat in cycles; these cycles are usually a result of the relationship between the async components. This is often the case when using patterns like worker threads, or async queues. The bug’s effects surface when the queue fills up.
Identifying the root cause of a race condition
Of course, the battle to vanquish race conditions doesn’t end by detecting them. The task still requires identifying the root cause that brought the race condition into existence. Turning to classic debugging is a solid option. Setting a good old breakpoint can be just the thing to get to the bottom line of a suspected race condition, but this can be tricky for two reasons.
The first reason is Replication. As we discussed before, race conditions are highly affected by the execution environment. This can make replicating the bug in a local environment extremely difficult. Worse still, even if we do manage to replicate the bug or, more accurately, an aspect of it, we can’t be sure of the precision of the replication.
The second reason is async behavior. Async flows are notoriously hard to debug with classic debuggers since setting a breakpoint and stopping one thread won’t stop the others. This will often affect the pace of the race or worse, throw the entire system out of balance. Due to this point of friction, regular debuggers often turn race conditions into Heisenbugs.
Addressing race conditions with minimum effort
While it may be tempting to turn to the dark-arts (necromancy and Test-Driven-Development 😉 ) do not despair. Here are some sure-fire ways to address race conditions with restrained effort:
Static analysis
The complexity that creates a race condition starts with the code running. Much of this complexity can be ignored by, well…simply not running the code. Reading the code and looking for the main suspects mentioned in the intuition section of this article, can not only identify a race condition but also its root cause. Combining this with attention to bottlenecks (e.g. shared resources, locks), and perhaps even old-school trace tables, can take us a long way.
Async reduction
Unlike with other, simpler bugs, reducing the application (i.e. gradually removing code until the bug disappears) won’t work so well. This is due to the cascading nature of race conditions. Instead, we can perform the race condition equivalent by removing async flows from the code and replacing them with synchronous ones. We can go through this process and replace flows with mock flows, or implement synchronization mechanisms on existing flows. This is obviously easier to do when we have a local environment in which we are able to replicate the bug. However, if we plan well, we can also apply this technique to live environments. This means taking the time to go over the suspect code elements for reduction and planning the steps and the versions/deployments needed prior to starting the process.
Production debugging
Production debugging, the modern version of debugging with non-breaking breakpoints is a good alternative to old-school debugging. It solves the replication problem by working directly on the live environment in which the race condition first raised its ugly head. It also solves the async flow problem since non-breaking breakpoints do not require stopping executing, thus maintaining the basic temporal aspects affecting the race condition. With production-grade debugging solutions, we can hunt down the race condition, by simply instrumenting and intercepting the various suspect points, until we hit the root cause. It’s still good to plan out the search path in advance. If needed, this technique can be combined with the async-reduction suggested above.
Resolving race conditions
Once we identify the root cause of a race condition, we need to fix it. No matter the reason, situation, environment, or other aspects of a particular bug, the resolution will always be one of two. We either separate the concurrent execution threads (threads, processes, microservices, etc.) making sure they do not affect one another at all by removing the dependency on a shared resource, for example. Or, we synchronize them and make sure that the order of the interactions is regulated when they do interact with a shared resource.
For synchronization, we usually need to pick one of two options: locks (e.g. mutex, spin-lock, semaphore, etc.) and atomic operations. The decision here is mostly dependent on constraints, solutions provided by the existing framework (Server, DB, etc.), and performance requirements (the more locks, the slower the solution would run – at best). My recommendation for you, fellow bug-slayer, is to start with the simplest solution that resolves the race condition, making sure the beast is dead and gone, and then considering optimization.
As important as it is to resolve a race condition, it is even more important to make sure it doesn’t return in other execution scenarios, or whenever someone changes the code. With race conditions, it’s best to use defensive programming. RAII techniques (Resource acquisition is initialization) are especially useful, both for preventing race conditions in the first place and for preventing their return. By applying RAII to the shared resources and other suspect bottlenecks as well as to the execution threads themselves, we’d make it a lot easier for developers to read and intuit race condition risk, and a lot harder for these sneaky bugs to slip in.
Happy hunting and Happy travels!
Related posts



