

Production Debugging: Everything You Need to Know
What is Production Debugging?
Production debugging, as the name suggests, takes place when one must debug the production environment and see the root cause of this problem. This is a form of debugging that can also be done remotely, as during the production phase, it may not be possible to debug within the local environment of the application. These production bugs are trickier to resolve as well, because the development team may not have access to the local environment when the problems do crop up.
Why production debugging is needed
In a perfect world, all errors and bugs would be caught in the development or QA phase. No differences would exist between the three environments, making the entire deployment workflow more robust and predictable. All settings would be uniform. However, the world is not perfect, and so this kind of complete uniformity is tough to achieve.
Consider, for example, an application heavily oriented around data (internal or third party). The data sets for production are not identical to the datasets for QA or development. In this case, problems may arise that were not caught in the early stages because the production environment uses a different, untested data set.
There are two possibilities in this scenario: either the data set will be made available to test in the other environments or there will be an effort to identify the problem and its solution directly within the production environment. When the latter possibility is realized, production debugging procedures are followed.
Advantages and Disadvantages of Production Debugging
Production debugging, as with all methods of debugging, has its pros and cons. Here are some of the most important ones to note:
Advantages:
- Development Speed: The sooner you find the root of the problem, the faster it can be resolved. Being able to identify and fix a problem while the application is in production without having to reproduce the error locally is a great advantage in terms of velocity. As this form of debugging can also be done remotely (more on this later), a developer need not spend time trying to access or replicate the local environment.
- Parallel Running: an application can be debugged in production without needing to shut it down. This is desirable, as the users can continue using the application while the bug is being fixed, allowing a seamless experience for the user.
Disadvantages:
- Affects Performance: Depending on the method used, troubleshooting an application running in production may have a negative impact on its performance. Even the lightest solution can impact the overall performance. Each log line is another code statement that needs to be run. If one uses a log-everything approach, then each log line will hamper the performance of the application.
- User Experience Risks: Modifying the application while it is being actively used can create unpredictable situations for your users and disrupt the overall user experience. It may slow the application down or cause unexpected bugs and errors that the user may encounter, prompting a poor experience.
Modern Infrastructure Challenges to Production Debugging
Today’s infrastructures are becoming more and more distributed. While this is mostly to maintain big applications efficiently, it is difficult to debug because it is difficult to trace the bug back to its source. In a distributed application, there are many moving parts, and when a problem occurs in the system, it must first be isolated to see its origin.
An example of such a phenomenon is serverless computing. Not only does it use a distributed architecture, but it represents an abstraction of the underlying application infrastructure and its abilities. In this architecture, the application is decoupled at the functional level, which is single-purpose, programmatic functions hosted on managed infrastructure.
Therefore, it’s almost impossible for a developer to perform a debugging process in normal conditions because the application does not run in a local environment.
Under these circumstances, developers need to gather enough information to solve the problem directly from the running application (function in case of serverless). Therefore, a remote troubleshooting procedure is required. As mentioned earlier, production debugging can also be done remotely through a remote debugging process.
What is Remote Debugging?
Remote debugging is debugging an application that does not run in your local environment. This is usually done by connecting the remotely running application to your development environment. In COVID times, this debugging method has become increasingly popular.
Remote Debugging vs. Classic Debugging
The core principle behind remote debugging and classic debugging is the same: you collect data from the concerned application and analyze it to find problems and their solutions.
In a classic debugging situation, you have all the tools you need. You run the application locally, and then based on your preferences, you can either run some tests, place a debugger, or write some log statements. If the problem originated internally and you can replicate the exact conditions within the local environment, the issue should be easy to solve.
For remote debugging, you don’t have the same flexibility. For example, with logs you only see the output you set before the deployment. However, if you want to log new information within the application, you would have to modify the code and deploy a new version of the application.
A debugger would have to install different tools on the server, run the application in debug mode, and remotely connect to it using some advanced IDE. This process will not only make the application nearly unresponsive for users, but also wouldn’t be possible as you don’t have access to the host server. Therefore, for remote debugging, either use information that you already have or search for new ways of collecting data.
How to debug in Remote or Production environments
When it comes to production debugging or remotely debugging an application in general, you can take some steps to reduce friction, both before and once the issue is already present.
Testing
One step you can take is to test the application in advance. By writing the correct automated test cases for your application you are able to drastically reduce the bug-potential-surface and detect prospective problems before they become costly.
There is no scenario in which you can say you tested everything and nothing could break. There can always be scenarios that were omitted or impossible to foresee in a test case, which is why testing can never be foolproof. Furthermore, this approach usually includes high costs in the form of heavy (and sometimes slow) R&D cycles, strenuous CI/CD infrastructure work, and strict testing requirements.
Testing is important and it should catch most of your bugs before you deploy the code, but it is not airtight. Here is what else you can do in case some bugs reach the production environment.
Define the Scope of your Debugging
You mainly need to figure out the root source of the problem. Did the issue originate from this service or did something else break in a different service and it cascaded here as well? The last thing you want to do when you try to solve a bug is to waste time by troubleshooting the wrong service.
Logging
Logging largely represents a process of collecting data about your application until you figure out the root cause. This approach has a lot of value when things go wrong and requires fixes. This is because the more data a developer collects, the higher the chance they will then have the required information to resolve the incident.
While logging is often something that is configured before deploying an application, it can also help to troubleshoot future issues.
However, with that being said, logging comes with downsides as well, such as logging too much or too little and performance issues.
Logging too much or too little
On the one hand, logging too much information will create an excess of information that will only make a developer’s job harder. On the other hand, logging too little may cause developers to miss pieces of information that would have helped them to understand the problem.
Simply put, a balance should be found for the amount of logging that you do. One way that this can be achieved is by logging at the proper level (bug, info warn, error, etc) and then splitting the levels into different files.
Performance issues
Writing log statements in your application achieves the goals of better understandability and observability for your application, helping you solve problems quickly. The last thing you want to do with log statements is to create new issues.
A logging statement is just another line of code that the compiler will execute. When you only have a few lines, the impact is almost 0. However, when you have thousands, the overall performance of the application will be diminished, especially if you aren’t logging efficiently.
For example, in a JavaScript ecosystem (this example is referring to NodeJS), the basic way of logging is using the console.log() method. The problem is that even if this is the easiest and most basic way of logging, this is not the most efficient. Proper loggers should be used like winston or morgan that don’t print messages on the console object.
Classic tools
If neither testing nor logging helps you to prevent or understand a problem and the incident can’t be replicated in a local environment, the next step is to use a special tool for remote debugging. These tools differ from environment to environment and can bring new challenges, as they can be difficult to install and configure.
For example, if you want to debug an application that is running on a Windows server, then you will need to download and install the remote tools on the Windows server. At the same time, you must be sure that you install the tools that match your versions. After this, you need to configure the server correctly to allow remote debugging. At the same time, running your production application in debug mode will make it almost unresponsive for the end users.
In addition to all of this, there may be cases where classic tools can’t be used at all. It could be because there is no access to the host as it is a serverless application, or perhaps they are too hard to configure. Classic tools are an option but there is not much that can be done with them, because rather than helping to quickly identify issues, they often only create more.
New Tools
As mentioned previously, the problem with classic tools is that they are difficult to use and they impact the performance of the application. Therefore, a tool is needed that does exactly what the classic tools do, but with none of the complications.
One of these tools is Rookout, a live remote debugging tool that is easy to use. It helps developers collect data from their application with no performance tradeoffs.
Here’s how Rookout differs from classic tools and how it solves the two previously mentioned problems.
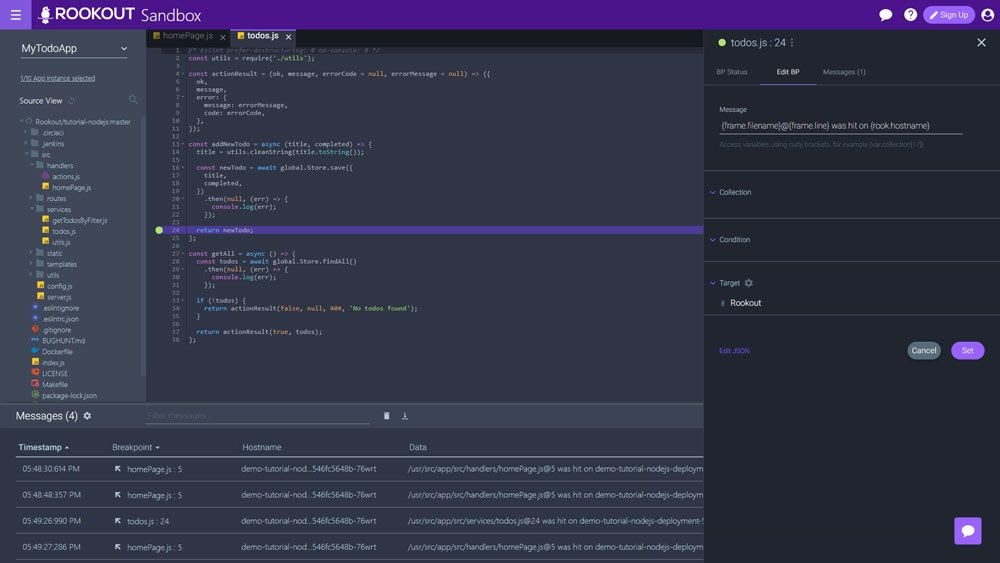
This tool is easy to use as all that needs to be done in order to connect it to an application is to install the library offered for the programming language of interest, and then add it in the project.

Rookout also introduces Non-Breaking Breakpoints. Once the application is connected with the tool, the developer can start a debugging session from the main dashboard as they would normally do in a local environment. The difference is that this time, they are doing it live on the remote server. Developers can set breakpoints and inspect the code without impacting the performance of the application.
Conclusion
Delivering a bug-free application to consumers is not a perfect or realistic process. Unique situations can still arise, either because nuances were missed in the development or testing phase or the production environment differs from the one used in development or testing. Nevertheless, developers should try to prevent as much as they can while staying prepared to address them if needed.
Read More
- Remote Debugging: Everything You Need to Know
- A Definitive Guide to Understandability
- Why to do Logging
- Software Testing Tips
- Python Debugging: More Than Just A (Print) Statement
Related posts



