The Anatomy of a Dev Team
A team of developers comprises several roles, with each contributing their own unique addition to the mix. Sometimes, it feels quite similar to every TV show ever about a slightly dysfunctional group of friends, (cough Friends, IT crowd, silicon valley cough), with each developer adding their own particular touch to not only the product, but the company vibe itself. They are each crucial to the success of the team, contributing their special talents and abilities and ensuring that the team runs smoothly.
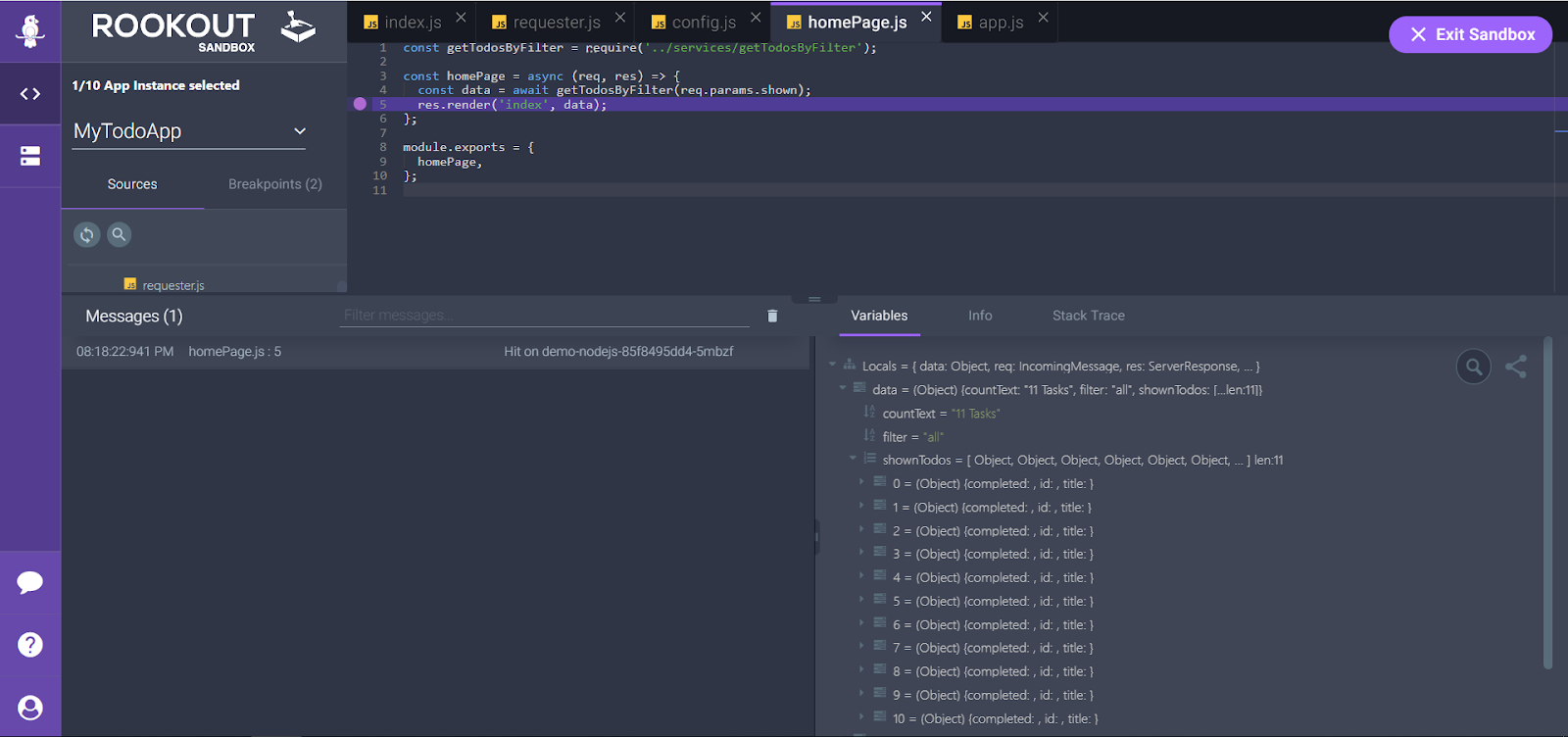
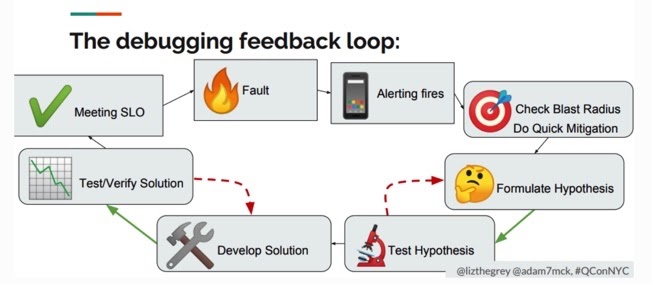
But what happens when an issue presents itself? Take for instance a situation where you get a certain piece of data from your backend, but this data is incorrect and/or misleading. It looks just as you’d expect it to, but it does not reflect the real state of your app. Depending on if and when your users notice it, this could be the difference between loving and embracing your product, or (the horror!) neglecting it for a competitor. So let’s go on a virtual game of ‘Guess Who’ and see who’s who of the dev team.
The dev team leader
The developer who is The dev team leader is often the one who has a holistic view of most things. This is the dev who reads code thoroughly, understands what it does, and avoids getting distracted (a small miracle!) by directed attention fatigue. This dev also communicates efficiently with the rest of the team to understand possible problem domains, draws control flow diagrams either mentally or physically, knows where to set logs or breakpoints as a result – and finally uses all of those to solve the issue.
When confronted with a problem – and even more so a problem related to misleading data – these are the steps that are likely to be taken by every team member. Yet, the Leader type is different, as they innovate and inspire others, but aren’t necessarily the team’s manager. Their ability to understand independently, and communicate the difficulties, challenges, possible solutions, and causes of the problem, is what makes them the maestros of the orchestra that is the dev team.
Depending on whether they are free or busy, they might choose to delegate the issue to the relevant team member or two, or just use their remarkable problem solving skills to do it themselves.

The Paranoid
We all know this dev. They’re absolutely certain that everyone is out to get them. If they work on microservice X and get corrupted data, then it’s surely microservice Y or Z that’s causing the issue (of course totally unrelated to them ). The Paranoid sets logs everywhere, which satisfies their need of feeling protected. As an added bonus, they also curse a lot – it could possibly be the multitude of log lines they’re now sorting through, but hey, don’t ask us- and carry a cup of coffee with them wherever they go. Are the two related? We’ll let you decide.
This is the dev who’s mostly quite good at what they do; they know how to make connections between problems and their domains, they know the majority of the system’s components even if they don’t work with all of them on a daily basis, and they are great mentors and problem solvers.
When it comes to data that is incorrect or misleading this dev goes nuts. They spray 15 different log statements in every file that calls a function that might have the slightest chance of affecting our data handling procedure. They somehow manage to pass a review or might be forced to remove a useless log line or two, leaving “just” 13-14 other log statements. They deploy to production.
When the data from the production environment arrives – it’s a hot mess. It contains a lot of data that may or may not be useful, with several contexts. However, sure enough, it helps our dev find the issue. It might take them another 5-6 log statements, some consulting with the infrastructure team, and a deployment or two, but hey, eventually they make it through. Bravo!

The “Character”
This dev takes their job seriously. As a possible overachiever, they get to the office in the morning, grab a cup of coffee, sit at their desk, and crunch away at whatever it is that they need to do to hit their personal goal – possibly and probably unrelated to actual business goals and absolutely related to their own personal standard of how things should be. When people mention them in random conversations around the office the first thing that comes to mind is “Now, that’s a character!”.
Aside from being very serious about what they do, these devs are great at problem solving and are some sort of human version of a Swiss army knife. They can get from A to Z with almost zero dependence on other parties and are phenomenal at what they do.
The Character would try to solve our problem by bringing out the big guns: they’ll start by seeing which queries are triggered by the client application, then they’d systematically add a log statement in a strategic location to avoid making too much noise in the company’s log aggregation service. Then they’d wait for a code review of that log, and after it’s approved – they’d merge to staging/master and deploy to production.
Hopefully not too long afterward, a wild log appears! And it contains just the info our beloved dev has been waiting for. They know exactly what the problem is, or at least where it originates from. They know how to proceed in order to solve it and they do it by themselves using the same strategy they’ve used so far. Eventually, they track the rogue SQL query and fix the bug independently. Joy.
The religious hipster
“Oh look! A new JavaScript framework!” – the religious Hipster, some time. Maybe. Probably. (Okay, definitely).
Of all our superstars, ninjas, rockstars, unicorns, or whatever you want to call them – this one stands out. Not because they’re particularly exceptional at what they do, but because of their perspective on things. These devs are well-informed of whatever it is that’s going on outside of their echo chamber that is their company. They’re well aware of whatever it is that other companies are doing to solve their problems, they thrive in developer communities, and they share their problems with other programmers to think of the best solutions – even when these solutions are a bit exaggerated. This dev wants to do it all with the newest tools that are available at their disposal, and if it depended on them – it wouldn’t matter how much it cost.
To solve the issue of incorrect or misleading data, they don’t want to waste time, but they might fail to realize that this exact ambition might make them look for the wrong, probably less-than-optimal, and time-consuming solutions.
They’d spend half a day looking for solutions that enable them to do some live debugging. This would lead them to some answers on StackOverflow about how to attach a debugger to their live testing/staging environment, using tools like gdb and others, depending on the platform. They would stumble across trending GitHub repositories that got some traction on Reddit, run some of them on their machines to test them out, only to realize that something isn’t working or that the repository itself is unmaintained.
After they’d realize this is a probable overkill, and that they’ve already wasted a lot of time for nothing – they’d go for the classic approach, maybe consult with a colleague, and place logs wherever needed. And 2 hours later? Bang, problem solved.

Teamwork Makes the Dream Work
Teamwork is important. You definitely have your own bunch of geniuses, each in their own field in your team, but having them work together is crucial for your team to succeed. During these times of distributed technology, having a distributed mindset in which all parties at least partly understand each other’s field and what they do, along with possible debugging strategies and understanding of their responsibility and work process, could make your team twice as successful, if not more than.
Ultimately, having your team share their knowledge with each other, amplifies and empowers each and every one of them, and yourself, regardless of whether you are the team leader or an individual contributor. The best way to have your team function optimally is to have 3 things available for them: understandability, independence, and asynchronous communication – with understandability being the most prominent.
Understandability and independence are achieved through mentoring and letting team members occasionally take a deep dive into a subject they’re unfamiliar with, or even just by solving bugs in an unfamiliar domain. Having one of your Front End developers take a look at infrastructure bugs along with minimal guidance can do wonders for both the team and themselves individually.
Gaining understandability into your code and your software leads to a skilled, capable workforce. So what is this holy grail of understandability? According to the financial industry, it means that a system’s information needs to be relayed in such a way that it’s easily comprehensible to the one receiving that information. Translating that into terms of your dev team, it means that the dev who is creating the software is able to easily receive and comprehend data from that software, and thus what is happening within it. Add all of this understanding together and bam! you got yourself a well-oiled and smooth-running dev team.

Related posts