How to Install Java Agents on Kubernetes
In today’s world of software development, it can often be challenging to get the data and information we need from running applications. While the introduction of container orchestration frameworks such as Kubernetes has brought about new capabilities around scalability and fault tolerance of applications, it has also introduced challenges in understanding exactly what’s happening within those applications when things don’t go as expected.
In some very unique ways, Java agents can be a powerful tool for helping us understand what’s happening within the internals of applications. Java agents provide the ability to instrument running applications through the modification of their underlying bytecode. In the case of Rookout, Java agents allow for deeper insights into the internal data of your applications whether they are running on your own machine, staging server or even in production.
With the prevalent adoption of microservice architectures across organizations, it is increasingly important to be able to roll out Java agents in a seamless manner, without impacting design decisions or causing rework of existing applications. So how easily can we deploy a Java Agent on our services running within Kubernetes? Let’s explore some methods of simplifying the deployment of those Java agents without major changes to existing services.
Deployment using environment variables
As mentioned in an earlier blog post (27 seconds to deploy a Java Agent), you can add a Java Agent to any JVM-based application using the JAVA_TOOL_OPTIONS environment variable. Doing this in a Kubernetes YAML file might look something like this:
apiVersion: v1
kind: Pod
spec:
containers:
– name: java-app-container
image: <image-name>
env:
– name: JAVA_TOOL_OPTIONS
value: -javaagent:agent.jar
For this to work, we have to load the agent jar file into the Docker container. But what if we don’t want to edit our existing Dockerfile, for example, using the ADD command?
ADD ./agent.jar /opt/application/path/agent.jar
Then what can we do?
Extending a base docker image
The easiest way to add a file to a Docker image without editing the Dockerfile is by adding another level of indirection. We create a new Dockerfile that uses our current application image as the base image, throw in whatever extra files we need, and deploy the new image to production:
FROM java-app:1.0
ADD ./agent.jar /opt/application/path/agent.jar # Add our agent jar file
Creating another level of indirection, and essentially another Dockerfile for each of your services is quite a hassle. Lucky for you, if you are already using a base Docker image for all your services (and if not, here’s why you should), you can utilize it to add the extra agent file to your image.
Getting better
But what happens if we don’t want to change our build and orchestration processes? Or, worse yet, what if we want to add a Java agent to Docker files that have already been built?
We can use the concept of Init Containers within our Kubernetes Pod along with a shared volume. The Init Container will download the agent file, store it on the shared volume, which can then be read and used by our application container:
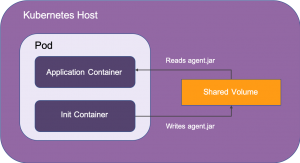
Our Kubernetes Pod template would look something like this:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
– name: java-app-container
image: <image-name>
initContainers:
– name: init-agent
image: <init-agent-image-name>
And the Dockerfile for our init agent image would look something like this:
FROM alpine:latest
RUN apk –no-cache add curl
RUN curl -L “https://repository.sonatype.org/service/local/artifact/maven/redirect?r=central-proxy&g=com.rookout&a=rook&v=LATEST” -o rook.jar
CMD [“cp”, “rook.jar”, “shared/volume/path/rook.jar”]
In this approach, the init container is run before the application container is started, making the agent jar file available to the running application. Plus, we didn’t have to touch our existing Dockerfile.
Summary
Installing a new tool is no small undertaking. It’s a journey that requires R&D investment and comes with a learning curve. We often find that we can significantly speed up the process using our DevOps knowledge and expertise. Whichever method you choose for installing your new Java agent on Kubernetes, Rookout will be there to help you troubleshoot.
Related posts