How To Not Freak Out When Designing A Product For Developers
Ever since the beginning of time, there have been two kinds of people: The left-brainers – methodical thinkers who use their logical and analytical skills to solve problems; and the right-brainers who tend to rely on feeling and intuition, are driven by inspiration and often think in a visual way.In today’s tech community, we often associate these two groups of people with designers and developers.
Of course, this statement is rather stereotypic. Designers often back their visual decisions on actual data and analytics, methodically analyze complex user flows, and sometimes (gasp!) even code. Developers think creatively, experimenting with different solutions to fit user needs and generally are pretty comfortable with design systems.


While we haven’t yet unified design and development, at the end of the day, both designers and developers are working toward the same goal: Building a product that best serves user needs, a product that looks good and functions properly.
The working relationship between designers and developers can sometimes be tricky, as each has a slightly different agenda and different perspectives through which they address the challenges that inevitably arise.
As the UX & design lead at Rookout, I’ve learned that the challenge is doubled when you’re designing a product whose users are developers.
These are a few lessons that I’ve learned through the process, as well as with some wise insights from fellow dev tool design leads from DataDog, Sentry & Alooma.
Know your user (but, like, really know him/her)
It’s quick, easy and very convenient to get answers when your user sits right across the table from you, and you hear him share everyday struggles and development work pains at the daily standup.
But it’s risky to rely solely on teammates when you’re defining your user. Like designers, developers come in different shapes and flavors. Front-end developers search for different solutions than back-end developers; data scientists have entirely different goals than devops engineers.

Beyond knowing your user, you should be aware of the specific state he or she is in when in need of your product.
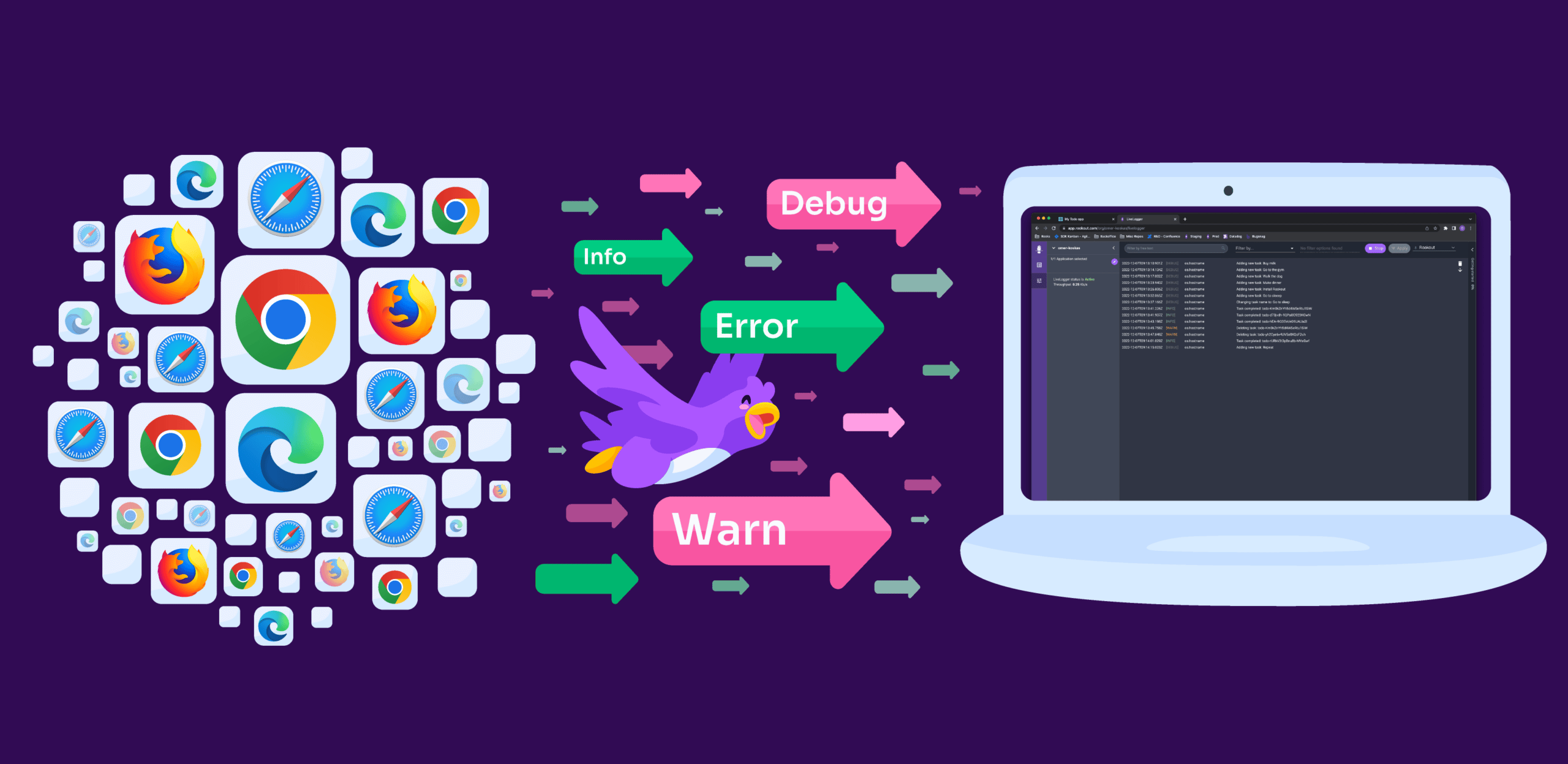
Rookout’s production debugging solution is designed to help the developer at a crucial point – when a bug or a performance issue has occurred and he must quickly understand what happened and resolve the problem. Lack of visibility and the limited ability to collect live data makes the debugging process feel like looking for a needle in the haystack in the dark.
Our user is frustrated and anxious, and in desperate need of valuable insights and support – someone that will say “Yes, you’re in the right direction!” or “No, you’re barking up the wrong tree,” and help him get things in order, quickly, before his own users are affected. So our design needs to reassure the user, while enabling him to find the answers he needs quickly and easily.
Software development is a religion
Remember that episode on Silicon Valley, where Richard freaks out when he learns that one of his employees commits a batch of code which is written using spaces and not tabs?
Sadly, this is not an exaggeration but rather a viable and blood-soaked war in the coding world.
Here’s how the Merriam-Webster Dictionary defines a “cult”:
1. A small religious group that is not part of a larger and more accepted religion and that has beliefs regarded by many people as extreme or dangerous.
2. A situation in which people admire and care about something or someone very much or too much.
3. A small group of very devoted supporters or fans.
Sound familiar?
Developers swear by their favorite framework, are devoted to their traditional tools, and have Sisyphean arguments about things which seem meaningless.

Developers can be resistant when it comes to changing familiar conventions – fonts, color themes, hierarchy. So you need to have pretty good reasons to back up unconventional design decisions. Yet designing within these conventions can limit your creative freedom. You need to find the right balance between good design decisions and fresh UI, and not unnecessarily shaking your users’ world.
We decided to go with a dark UI for Rookout’s app after researching which IDE interface is developers’ favorite. White-on-black themes are popular among developers who want to minimize eye strain while spending hours in front of computer screens. They have good readability and high contrast. In fact, over 70% of software engineers code on dark theme IDE’s. So all in all, it seemed reasonable to keep Rookout’s theme consistent with the rest of our users’ environment.
Some Rookout design components, however, had to be invented from scratch. For example, the rules concept in Rookout is something that can’t be found in IDEs or similar tools. So we had a great opportunity to combine work within established conventions with designing something completely new and fresh, from scratch. All in all, it was a great challenge and very satisfying.
Developers are people, too
Contrary to popular opinion, and despite developers’ well-deserved reputations as sophisticated and tech-savvy (obviously) users, they are still people. And like most people, they expect products to serve their needs as quickly and effortlessly as possible. They don’t want super-complex tools that take hours to learn.
This important input came through loud and clear in almost every user interview we conducted: Make the user interface as intuitive and simple as can be. Don’t assume that because developers are smart, they will figure it out. If they don’t get it, they’re probably not gonna keep trying.

Less is more
Dribble and Behance are full of gorgeous design concepts, perfectly aligned tables and gradient dashboards which look amazing as screenshots but fail to function in the real world.
A beautiful application that is not functional will not satisfy users’ basic needs. Users tend to remember the bad more than the good. Can you imagine your user saying, “This app takes ages to load and I’m not really sure what all these buttons do, but, boy! This splash screen animation is super cute!”?
Only when a product is functional, reliable, and usable can users appreciate the delightful aspects of the experience.
Sentry‘s co-founder and head designer, Chris Jennings, was, in fact, a product designer at GitHub before making the transition and creating an error tracking tool for developers. Here’s what he had to say about why, especially for developers, less is more:
“If there’s one-way developers are different from the average consumer, it’s that they don’t have a lot of patience for fluff or interruptions. Our customers use Sentry to solve some pretty gnarly problems and part of our job is to make sure we don’t get in the way of that with things that aren’t 100% necessary.”

Don’t be afraid to ask for help
Gitit Bruetbart, Senior Product Designer at Alooma, says she regularly sources insight about usability and product design from her friends, who are generally happy to explain technical issues and contribute their thoughts.
“As a designer, entering the world of developers is not always easy,” she explained. “While designers are up close and personal with product technology, they are rarely as familiar with the technical issues and terminology as developers are. Fortunately, however, in startups, designers and developers work closely together or at least socialize over lunch.
“When I need to do usability testing, I can generally find testers that fit the exact persona of our target audience among these friends, or among their friends who are developers in other startups, They’re happy to try out interesting new tools (and to get a small token of my appreciation), and I get the benefit of their insights and feedback.”
Ultimately, it’s all about the people
When it comes to a new product, good design is a make-or-break factor of success. But, as Stephen Boak, director of product design at DataDog and host of the amazing podcast ‘Don’t Make Me Code’ points out, “The communities that develop around our tools can also make or break the experience, especially in the world of open-source. The community you build, the evangelists you create, and the quality of your ecosystem will make the experience better for everyone. Think of Twitter and what they’ve done with their API to alienate developers.”

In the spirit of building a positive and supportive Rookout community, I invite you to share your thoughts on designing a dev product. If you’re a designer, how do you make sure the design is aligned with dev needs, preferences and expectations? And if you’re a developer, let me know what design features and elements make your favorite tools a pleasure to use.
* Originally published on TheNextWeb
Related posts