The Essential List of Spring & Spring Boot Annotations for Getting Started and Configuration
Spring Boot has made the Spring Framework more accessible than it already was. It is a streamlined form of the larger Spring Framework. For one, Spring uses manual configurations while Spring Boot contains a number of default config templates. Spring has a number of dependencies; Spring Boot, not so much (at least until build time). Auto-configuration makes it easy to get started with the Spring Framework (or even Java overall if you’re a true novice to coding) and the support community is huge.
One of the more overwhelming elements of Spring and Spring Boot is the extremely long lists of classes and annotations that exist. The documentation is extremely thorough, but complex.
There is also mapping out (in your own mind) what works at a method level and what works at a class level; should something be defined specifically as a bean or component (we’ll get to those soon); and what needs to be annotated and what doesn’t.
This is just a selection of the many annotations Spring Boot and Spring have, with a focus on the basics, configurations, and testing.
Basic Spring & Spring Boot Annotations
@Bean – This is the #1 concept to know in Spring. A bean is an essential component of any Spring-based application. That is the most basic understanding. That being said, you should consider more advanced understandings of what actually constitutes or should be defined as a bean. There is the definition from the Spring docs:
“In Spring, the objects that form the backbone of your application and that are managed by the Spring IoC container are called beans. A bean is an object that is instantiated, assembled, and otherwise managed by a Spring IoC container.”
IoC refers to “inversion of control.” Basically, you define control by declaring dependencies. This is why IoC containers are often also called a “dependency injection container” (or simply ‘DI containers’). There are two kinds of containers: the simpler BeanFactory and more extended ApplicationContext (which includes capabilities like Spring AOP, a web app layer, event propagation, and message handling.
Stereotype Annotations and Bean Configurations
The automatic dependency injection connecting these components and their dependencies – in other words, between the beans – is called autowiring. Spring will use beans at their designated time based on what stereotype annotations you set. Here are some of those stereotype annotations:
@Component– Annotates class as a component. Brass tacks,@Beanonly declares something a bean;@Componentdetects and configures them.@ComponentScan– Configures component scanning@Compenent,@Service,@Controller, and@Repository@Service– Creates beans on the Service layer@Repository– Creates beans for repos on the DAO layer@Controller– Creates beans on the Controller layer@RestController– Marks annotated class as a@Controllerbean and adds@ResponseBodyto serialize returned results as messages
@SpringBootApplication – This annotation combines calls made by the following 4 annotations:
@Configuration– Marks annotated class as a Java configuration defining beans@SpringBootConfiguration– Indicates Spring Boot application<code>@Configuration@EnableAutoConfiguration– EnablesApplicationContextauto-configuration to provide possibly needed beans based on theclasspath@ConfigurationProperties– Note that@ConfigurationPropertiesScanwill auto-detect@ConfigurationPropertiesclasses
Properties
@Autowired – This marks something to be autowired
@Configurable – This annotation indicates something is eligible for configuration
@Qualifier – This can explicitly name a bean (field or parameter in this case) eligible for autowiring
@Value – Indicated a default value for a parameter
@Lookup – This simply defines the <span style="font-weight: 400;">lookup</span> parameters
Conditional Spring Boot Annotations
There are a number of specific conditionals listed below. However, by no means is this an exhaustive list. In fact, you should assume the full list of conditional annotations will see constant updates, so make sure to refer to the docs if you need a very comprehensive list of options beyond these common and core condition annotations.
@Conditional – Of course, the first one we need to mention is @Conditional. This conditions the implementation of a bean, based on any of the defined conditions under this annotation.
Base a condition on if a specific class, bean, or web application exists or not:
@ConditionalOnClass&@ConditionalOnMissingClass@ConditionalOnBean&@ConditionalOnMissingBean@ConditionalOnWebApplication&@ConditionalOnNotWebApplication
@ConditionalOnProperty – This conditions creating an object or service on the value of a config property.
@ConditionalOnExpression – This conditions creating an object or service on an expression (i.e., a combo of sub-conditions).
@ConditionalOnJava – This annotation is clever. Considering you could be running different versions of Java, you may or may not want to run certain services depending on the version of Java you’re on. So, you can condition a new service on having a given version:
@Service
@ConditionalOnJava(JavaVersion.SIXTEEN)
class LogFactoryNotFactorial {
// ...
}@Service
@ConditionalOnJava(Range.OLDER_THAN, JavaVersion.SEVENTEEN)
class LogFactory {
// ...
}Web AnnotationsYou can also specify a range of versions using ConditionalOnJava.Range, followed by values, as well as additional parameters EQUAL_OR_NEWER or OLDER_THAN.
@RequestMapping is the original mapping annotation for Spring to map any and all HTTP request URLs. They provided the request methods with that information, Spring 4.3 introduced specific notations for those specific calls:
@GetMapping(by the way, there is an identical annotation in Spring’s GraphQL API package)@PostMapping@PutMapping@DeleteMapping@PatchMapping
@RequestParam – This accesses the parameters of HTTP requests, while @RequestBody maps the body of the request.
@GetMapping("users")
public @ResponseBody ResponseEntity<List<User>> getAll() {
return new ResponseEntity<List>(userService.getAll());
}
@GetMapping("users/{id}")
public @ResponseBody ResponseEntity<User> getById(@RequestParam(user = "id")Testing & Validation
@SpringJUnitConfig is a composed annotation that combines the following two annotations:
@ExtendWithfrom JUnit Jupiter, which defines extensions for tests, and …@ContextConfigurationfrom the Spring TestContext Framework, which defines class metadata and how to configure an<span style="font-weight: 400;">ApplicationContext</span>
@SpringJUnitWebConfig goes even further by adding a third annotation to the above: @WebAppConfiguration.
@TestPropertySource– This defines the locations() of properties() to add to PropertySources
@DirtiesContext – This indicates that an <span style="font-weight: 400;">ApplicationContext</span> should be closed and removed from the context cache (<a href="https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/test/context/cache/package-summary.html"><span style="font-weight: 400;">ContextCache</span></a>). In other words, it’s ‘dirty.’ If a test modifies the state of some bean, database, or object, then this will indicate the context should be ‘cleaned’ and replaced with a new context.
@Sql – designates a test class or test method used to configure SQL scripts and statements for tests. There are related annotations:
@Sqlconfigdefines metadata for parsing those SQL scripts.@SqlGroupaggregates multiple@Sqlannotations, while@SqlMergeModeis used when both 1) method-level and 2) class-level@Sqldeclarations are merged together.
@EnabledIf and @DisabledIf define when a test class or method should be enabled.
@ActiveProfiles – Declares which active bean definition profiles to use in <span style="font-weight: 400;">ApplicationContext</span>. This is only one of the annotations that are part of the Spring TestContext Framework.
@SpringBootTest – This annotation will load an entire ApplicationContext – all layers – for testing
@WebMvcTest – Load ONLY the web layer
@DataJpaTest – Load ONLY the JPA components
@Mock – Defines something as a mock, or a mock object.
@MockBean – Marks something as a mock and loads it as a bean in <span style="font-weight: 400;">ApplicationContext</span>
@Valid – Mark nested properties for validation at the method level (method parameters and fields)
@Validated – Mark properties for validation at the class level as part of group validation
Other test annotations include @Commit, @Timed, @Repeat, @Rollback, @DirtiesContext, @IfProfileValue, and @ProfileValueSourceConfiguration.
Springing Forward
You’re not going to find anyone giving you a “complete” list of Spring Boot annotations outside of the massive Spring Boot Docs index. That being said, Spring and Spring Boot constitute a compendium of streamlined options for Java developers who want to make something quickly.
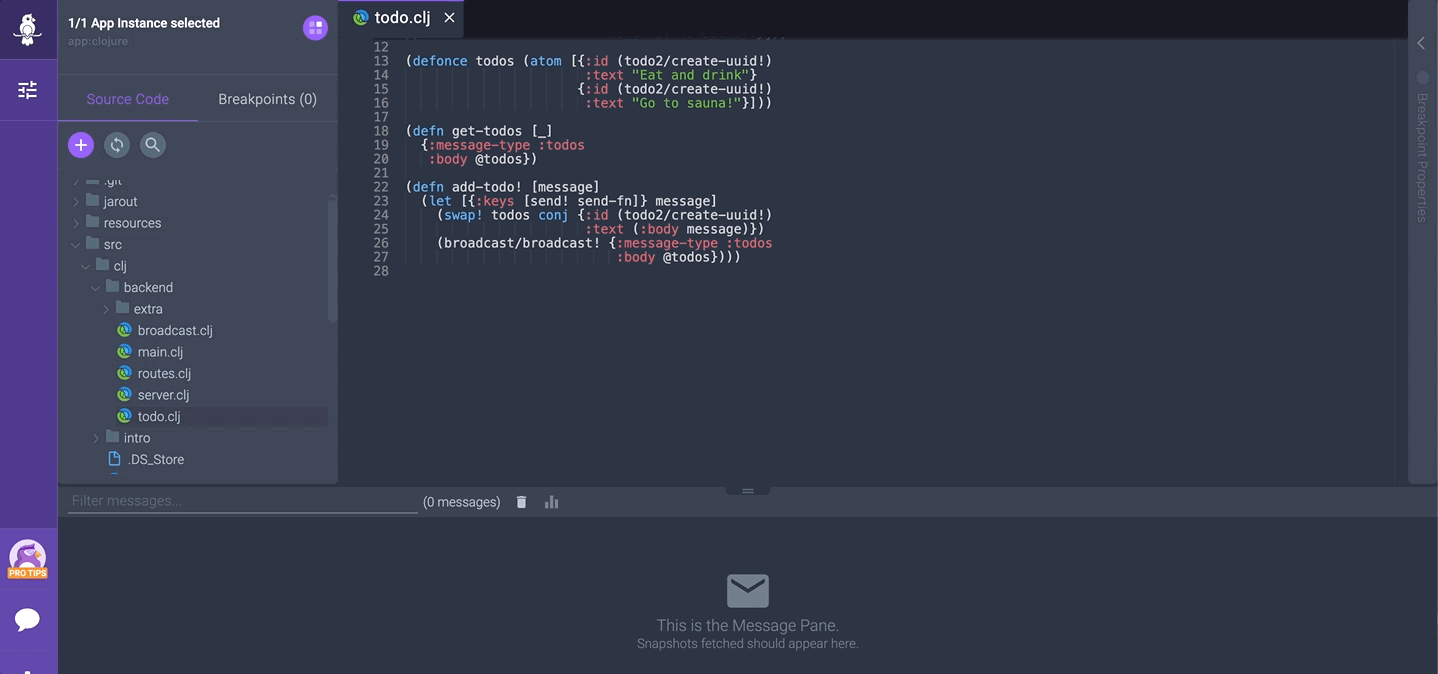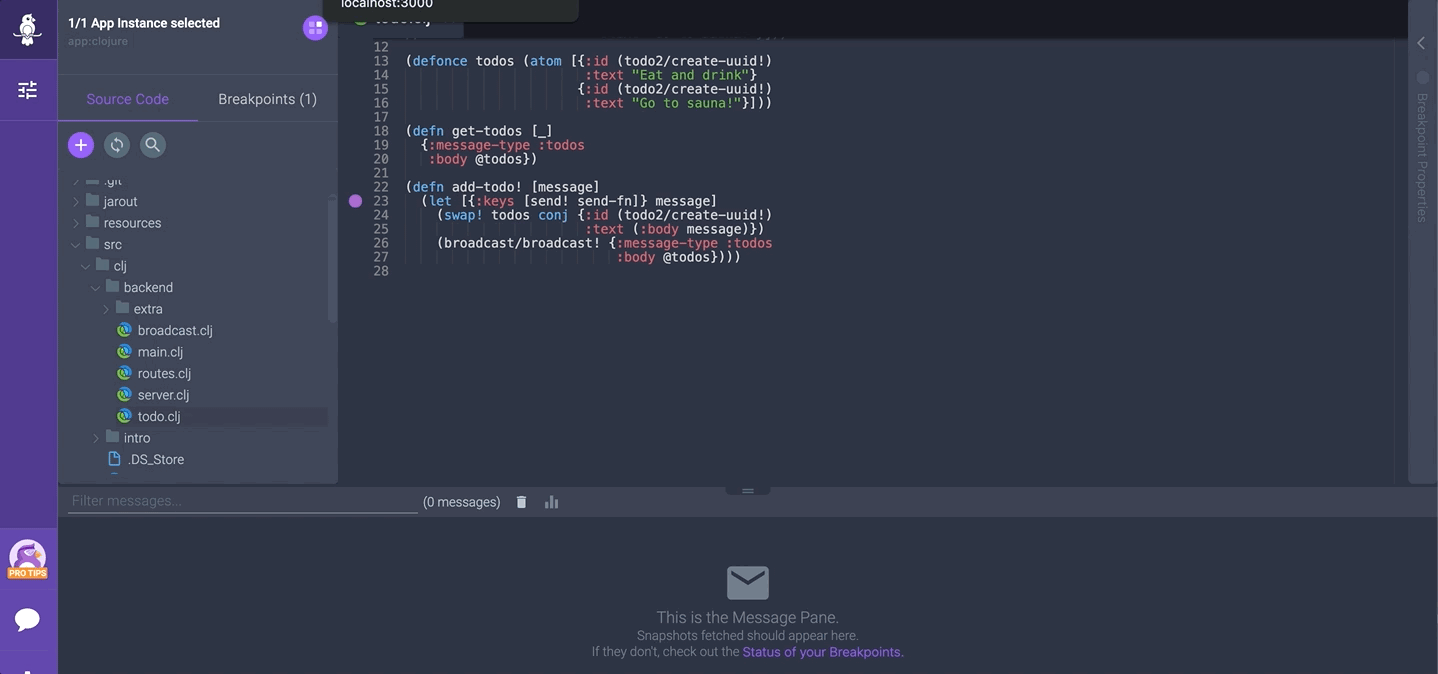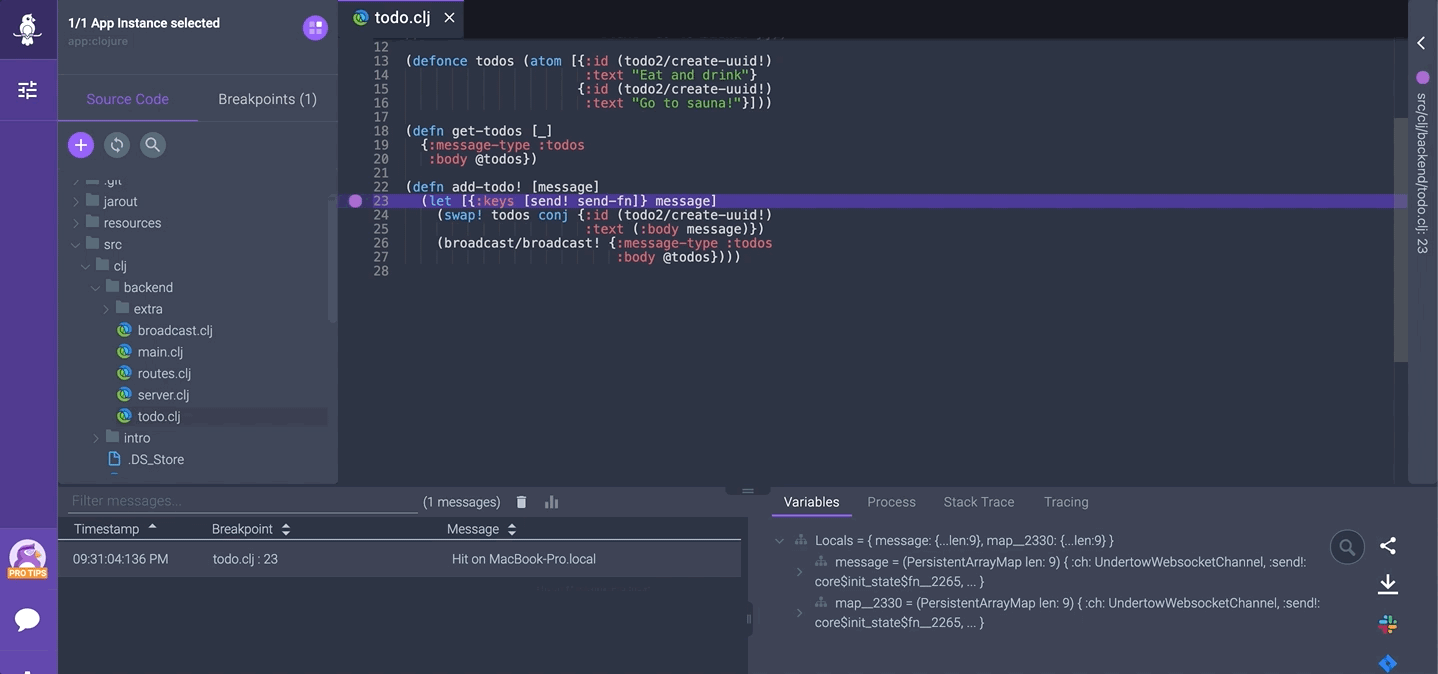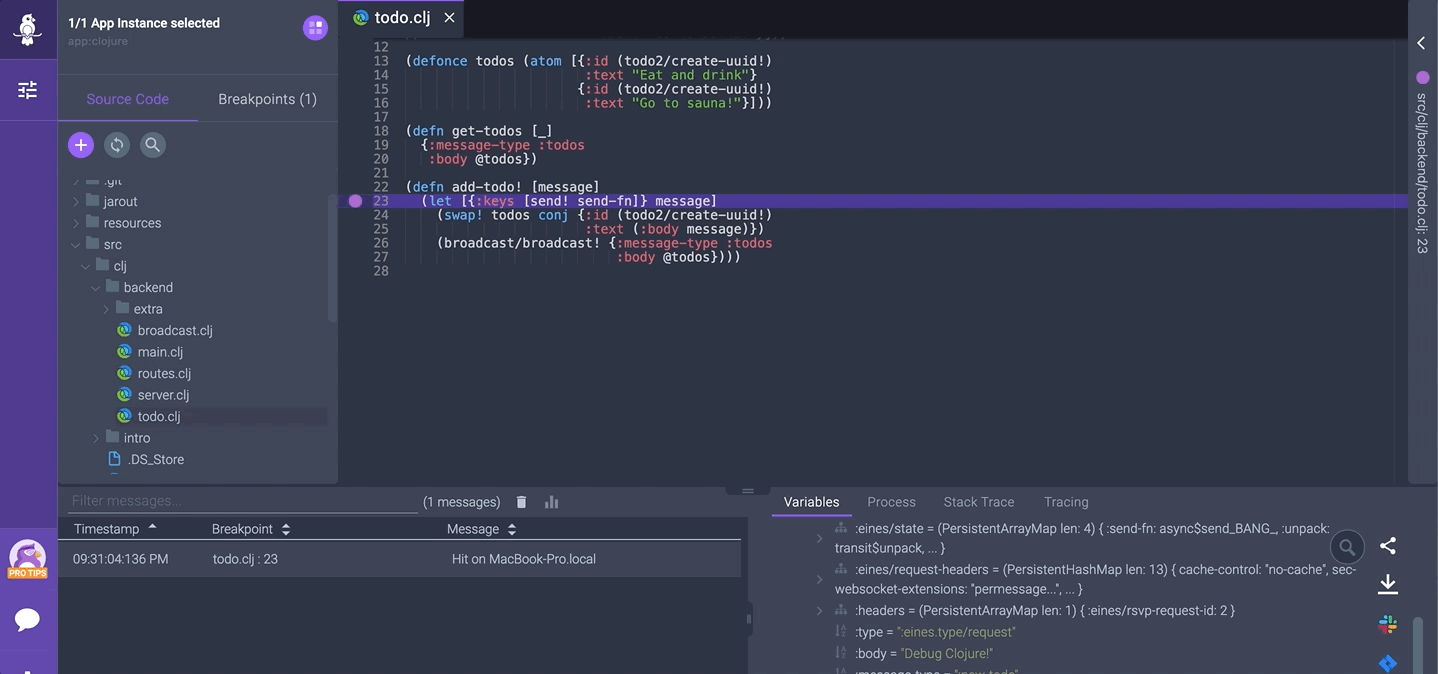
There are more domains to cover in Spring, including troubleshooting. When it comes to observability and debugging Spring Boot apps, Rookout is one of the tools that you can use to help you out.
Whether they are just starting out, testing an idea, or creating something for a tutorial, the rigid and expansive list of annotations and classes is a gift for the Java ecosystem that keeps on giving.
Related posts










.png)