Golang (or just Go) is a well-established programming language ground built for speed and efficiency. Robert Griesemer, Rob Pike, and Ken Thompson designed the language at Google. It was first announced to the public in 2009 and it was made open source in 2012.
Go is the preferred choice among developers, but its simplicity can also leave it vulnerable to bugs and other programming issues.
In this article, you will learn about common bugs in Golang programs, as well as some of the traditional approaches used to debug them. You’ll also learn about emerging tools like live debuggers available for Go debugging, which are similar to classic debuggers but can help you get instant debug data and troubleshoot easily and quickly without adding new code or waiting for a new deployment.
Why Choose Golang?
There are several reasons to use Go. Here are some of the biggest benefits:
- Learning Curve – Golang is one of the simplest programming languages available, so it’s easy to work with.
- Excellent Documentation – The documentation is straightforward and informative.
- Great Community – The Golang community is supportive, and you can get help through Slack, Discord, and even Twitter.
- Build Anything – Golang can be used to build anything from standalone desktop apps to cloud apps. Go also has concurrency, which means it can run multiple tasks simultaneously.
- Goroutines – The introduction of goroutines, or activities that execute concurrently, has made Go a great choice for programmers as well as for DevOps engineers. Goroutines are cheaper than using threads, and the stack size of a
goroutine can shrink or grow according to the need of the application. Another benefit of goroutines is that they communicate using channels, which prevent race conditions from happening when accessing shared memory.
Despite its useful features, debugging in Golang can sometimes be frustrating. The print statement is often used to debug small programs, but this can complicate the process when working with a large program. Typical debuggers offer limited features even though they work with Golang. Some features of Golang can confuse debuggers and cause incorrect outputs. Because of such issues, it is important to know which tool to use when debugging Golang.
Common Bugs in Go
One of the common bugs to watch out for is infinite recursive calls. If you do not add an exit condition inside a recursive function, the function will run until the system runs out of memory.
Another common mistake by beginners in Go is assigning entry in nil map. Assigning a value using the below syntax will create a panic error:
var m map[string]float64
m["pi"] = 3.1416
This is because the map must be initialized with the make method.
m := make(map[string]float64)
m["pi"] = 3.1416
There are other mistakes that developers should be aware of as well. Check this article to learn more about them.
Debugging in Go
Golang is still a relatively new language, and some of its nuances aren’t commonly known yet. This can lead to problems when writing code.
As noted, one standard option for debugging is to use the print statement. Another is the open-source debugger GDB. But GDB wasn’t explicitly built for many newer features of the language, such as Goroutines. The Delve debugger was designed to address this need.
Another option is using the Log package to create custom logs for your code.
Following are details on the various options.
Go Print Statements
The most common way of debugging code in any programming language is using print statements. This is the first approach most developers take because it’s easy to get started by importing the fmt package into the code. You don’t need to install a third-party tool. However, this approach is not as comprehensive as others.
The fmt package in Golang provides three ways to print anything to the console:
- printf, which allows you to format the numbers, variables, and strings;
- print, which only prints the string passed as an argument; and
- println, which does the same thing as
Print, then adds a new line character (\n) at the end of the string passed to it.
Logging
Logging is another method of debugging code in any programming language. But systematic logging can also be done too broadly without considering the use case, leading to spam logs and further problems.
For basic logging, importing the default log package is enough. Here’s an example snippet:
package main
import (
“log”
)
func main() {
var a int = 10
log.Print(“logging the value of a. a =”, a)
}
Running this code will give you a log and the date and time.
You can also take it a step further and integrate with the OS package to write the logs into a new file. This is the standard approach when using logging as a debugging method.
With a proper logging method and format implemented, you can catch errors more quickly. You can also automate logging notifications so that you’re notified whenever something goes wrong. Even if you use a different method to debug your code, it is always a good idea to implement a proper logging system.
The default log package works well, but third-party logging frameworks are also available. Two common choices are glog and logrus.
Delve
One of the most popular options, Delve offers an easy-to-use, full-featured Go debugging tool.
To get started with Delve, install it on your machine using the following line:
go install github.com/go-delve/delve/cmd/dlv@latest
For macOS, you also need to install the developer tools. Check the official documentation for instructions.
You can check if Delve is installed on your computer by typing the dlv command into the terminal. You should see an output similar to the below image if you were successful:
You can also check the version by typing dlv version in the terminal:
See what Delve has to offer by using the dlv help command in the terminal. To debug a program, execute the dlv debug command. Attach the filename at the end of this command, and debugging will start. For example, if you want to debug the main.go file, run the command dlv debug main.go. It is also known as “delve server” because this is a running process waiting for instructions.
After entering the repl provided by Delve, check the available commands using the help command. You can also check the (nearly) full list of Delve commands.
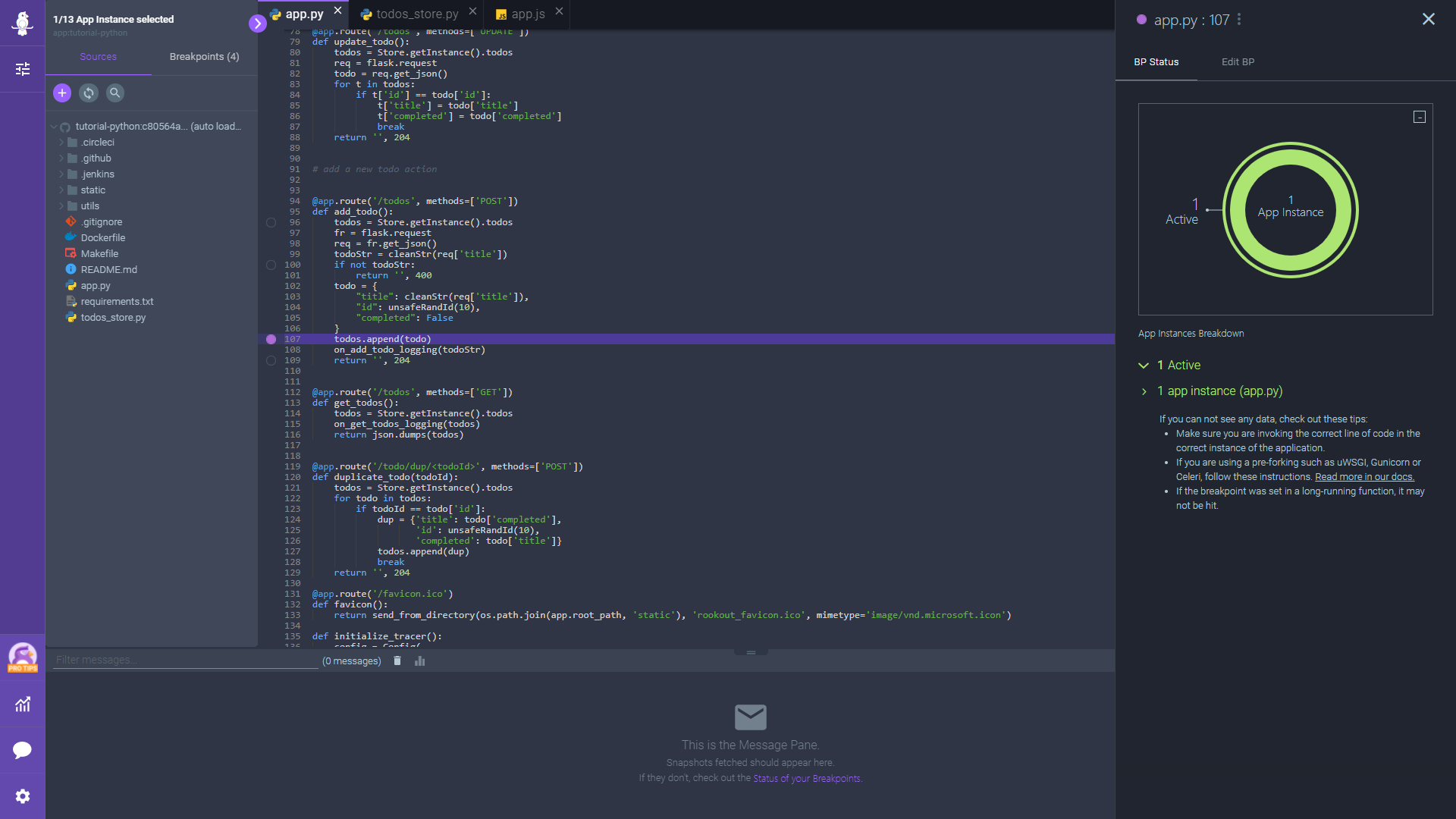
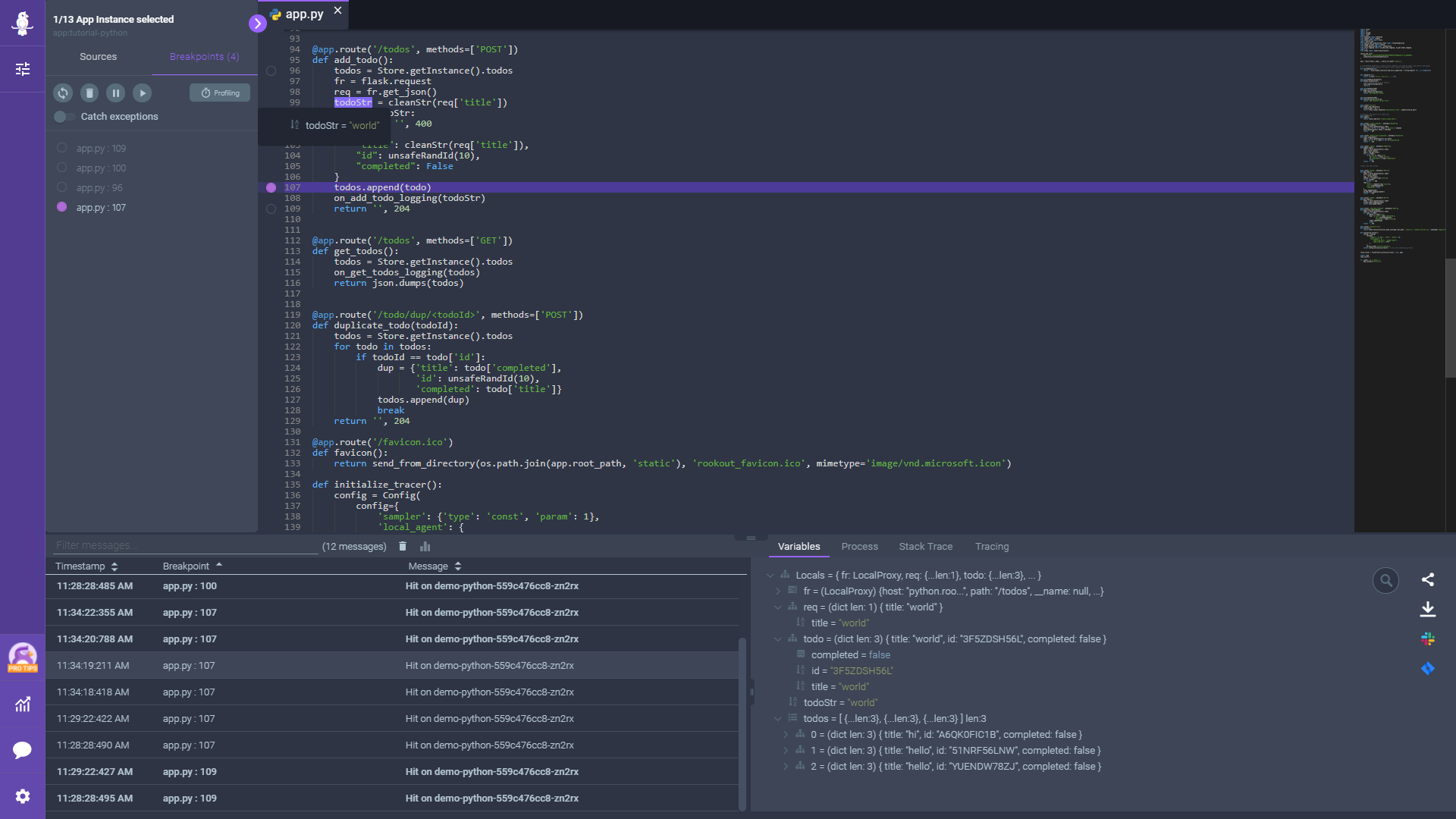
Breakpoints
Breakpoints are at the heart of debugging. They help to stop and inspect the variables and other expressions. You can use the break command to add breakpoints in your code.
For example, if you want to add a breakpoint at line 5, run:
Once your breakpoints are added, use the breakpoints command to view them. Running the command clearall will clear all breakpoints.
When you use the continue command, the debugger will run the code and stop at the next breakpoint you have set up. If there is no breakpoint, it will execute until the program terminates. For more details on the commands, check the Delve documentation.
VS Code
Visual Studio Code is an integrated development environment (IDE). It is perceived to be the most popular IDE among developers, according to Stack Overflow 2021. It was initially built by Microsoft in 2015, which later on released it as an open-source project.
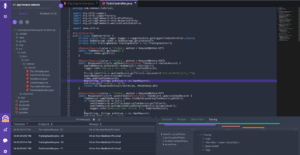
It allows you to build, edit, and debug programs. If you use VS Code to run your Go code and have the official Go extension installed on the editor, you can debug your code by pressing F5 or Run and Debug on your computer. For that, you’ll have to install Delve as a prerequisite.
To install Delve on VS Code, run the combination Ctrl+Shift+P or Cmd+Shift+P on Windows or Mac, choose Go: Install/Update tools, search “dlv,” and install it.
Running F5 or choosing Run and Debug can help you get started with debugging. Clicking on the area beside the line numbers will let you add breakpoints in your code.
Golang debugging in VS Code, courtesy of GitHub
Running this debugger the first time will ask you to install the dlv-dap, which you need to make the debugger work. The debugger will give you a graphical user interface to see what’s happening in your code. This approach is much better for beginners than handling the CLI.
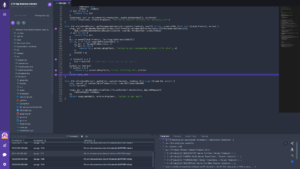
Running the debugger will create a new file launch.json in your working directory inside a new folder called .vscode. You can configure the debugger here. By default, a <span style="font-weight: launch.json file looks like this:
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
“version”: “0.2.0”,
“configurations”: [
{
“name”: “Launch Package”,
“type”: “go”,
“request”: “launch”,
“mode”: “auto”,
“program”: “${fileDirname}”
}
]
}
You can specify environment variables in this file using the "env": {"KEY": "xxxxxxx"} attribute. You can also specify the .env file location to look for when debugging, which can be defined with "envFile": "${workspaceFolder}/.env". The workspaceFolder is a variable that refers to the path of the open directory. You can check the list for all the reference variables.
Debugging with VS Code is discussed in detail in the documentation.
GoLand
The JetBrains-powered GoLand is another powerful IDE used for Golang development. GoLand provides a GUI for debugging and works with Delve.
To start the debugger, you can either click on the green triangle and choose to debug, or right-click on the folder and select Debug. JetBrains offers more details about debugging with GoLand on its blog.
If you prefer a GUI to CLI, debugging with VS Code or GoLand is a great option. They offer the same functionality as Delve and a graphical interface.
goimports & gofmt
The goimports package in Go isn’t a debugger, but it can help you reduce bugs by removing mistakes from the codebase. goimports adds missing imports, sorts them, and groups them into native Go and third-party modules. Check the documentation for more details.
Similarly, the gofmt tool is used to check the code formatting, which is important because Go code is formatting sensitive. Here is an example of how to use gofmt:
package main
import (
“fmt”
“log”
)
func main() {
var a int = 10
fmt.Println(“a =”, a)
log.Print(“logging the value of a. a =”, a)
}
Running the gofmt command switches to the below format:
package main
import (
“fmt”
“log”
)
func main() {
var a int = 10
fmt.Println(“a =”, a)
log.Print(“logging the value of a. a =”, a) //implementing logging
}
In VS Code, the gofmt command runs every time you save your file.
These tools can help you avoid bugs by catching minor mistakes that you might miss.
Live Go Debugging
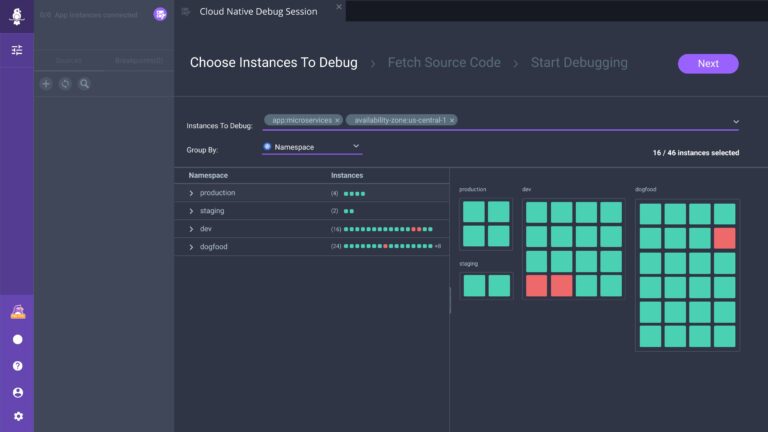
Another option for debugging is a live debugging tool. Such tools are dedicated services powered by dynamic instrumentation, such as Rookout. Rookout supports debugging Go applications, as well as other languages, and provides real-time access to your code across all environments. It also allows you to generate and check metrics like execution time.
When using Rookout, you don’t have to use an SSH key to get data from your dynamically deployed application. Its unique capability is the real-time access to your code-level data with no need to add code or wait for new deployment, which dramatically reduces the amount of time spent on modern app debugging.
Conclusion
Golang debugging is a must-have skill for developers. Using a debugging tool or an IDE with your Go programs is an easy way to ensure a healthy and functioning code. Making sure you use the quickest route to your root-cause will save countless hours and resources on fixing errors, so you can achieve a quicker workflow and a better-quality product.
We have a fully compatible Go SDK for you to try out. To give Rookout a try, you can sign up for a free trial or check out its sandbox.


























![[Let there be logging light]](https://www.rookout.com/wp-content/uploads/2021/08/Yoda-768x474-1.jpg)
![[Switch a powerful searchlight on to fetch in-context logs]](https://www.rookout.com/wp-content/uploads/2021/08/batman-768x432-1.jpg)
![[Light up your observability platform without setting your app on fire]](https://www.rookout.com/wp-content/uploads/2021/08/globe-768x576-1.png)