The Bare Necessities of Live Application Debugging
As R&D managers, we want to make sure our developers are happy and efficient. We want to ensure that they have the bare necessities they require to develop the best applications, whether it be the right desktops, the right headset, the right brand of coffee, and as many cookies as our budget can afford.
In some areas we take their personal preferences and their professional recommendations into account when applicable, such as when choosing a coding language, an IDE, an open source framework, or a cloud vendor. In other areas we choose for them, like when security and compliance are on the line, when their preferred choice is beyond our budget, or when we have our own professional considerations that don’t fully align with theirs and even conflicts with their preference. Our developers don’t like being tracked on the progress of their tasks, yet we choose a tool and a process for managing releases and tracking tasks.
Tool choice considerations
Some tool selections feel like a bonus we can give our developers. When using their favorite IDE, for example, developers are happier and more efficient. Other tools are crucial to the efficiency of the team, to the quality of the product, to the success of the business. Our developers wouldn’t necessarily choose to use an exception catching tool, yet we know that in order to spot and resolve issues quickly, we should have one in place.
Another common consideration in tool selection is whether it feels necessary or not. When considering some tools, we wonder whether they will actually be used by our team or if they really only sound nice in theory. We try to imagine how our team will adopt the tool, what may prevent them from using it, and how often it will get used. It is not uncommon that we are so used to doing things the long and difficult way, that we can’t imagine changing our workflow.
When considering a Live Debugging solution, it is sometimes unclear, at first glance, as to which category it belongs. Sure enough, if your team struggles with solving production issues on a daily basis, or if there are certain technologies and deployments you just can’t reach with your local debugger, well, adding a Live Debugger into your tech stack is a no brainer. In other cases, at first it may seem that the choice isn’t as clear cut. Let’s examine the reasons and rationalization that impact us when we find ourselves hesitating on whether or not to introduce Live Debugging into our developer’s toolbox.

An urgent need of a sense of urgency
Take a minute and ask yourself the following questions (and try to answer them honestly 😉 ). How many customer issues does your team handle? How long, on average, does it take your team to handle each issue? And where is the majority of that time spent?
Some of us have very clear answers. We are required to report these numbers as KPIs of our R&D organization. We understand every support ticket is a potential for an unsatisfied customer and that every minute of downtime can immediately be translated into a loss of business transactions. We measure our response to incidents and present our progress on a weekly or monthly basis.
Some of us, however, don’t think this is an urgent issue. We think the number of escalated cases is small, and that our team is “probably good enough at dealing with them, otherwise we would have heard about it”.
In my experience, if that is your response, you likely belong to one of two groups. Either your team and your product are indeed that good, and if that’s the case I really have nothing to offer you. But the far more likely case is that things are so bad you don’t even have the time to measure how bad they are. And if that’s the case, you may want to free up some time for you and your team by adopting a technology and a skill that will help you solve these incidents much, much faster.
New things seem hard before you try them
Whenever a new tool is introduced, some friction is to be expected. This is usually based on our own experience as developers or as managers who have already tried to introduce some tools. Tools require an installation, some training, and worst of all – the ability to adapt and change the way you and your team do things. That last part about adapting to change is especially hard to handle when working with developers, who are very sensitive due to their already complex and challenging work environment.
And as we’ve hinted earlier in this article, developers are specifically sensitive to having tools “dictated” to them by management or by the company.
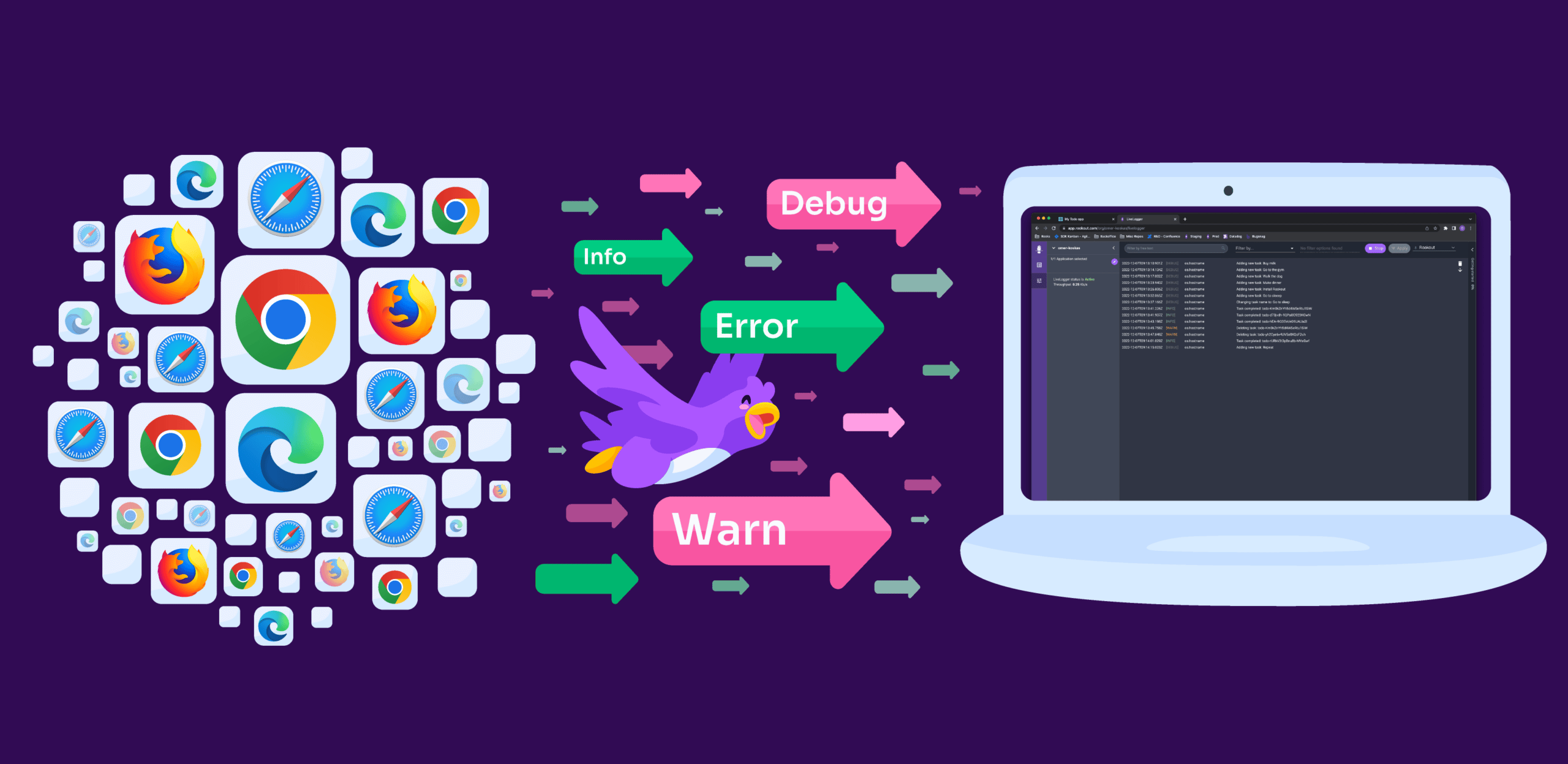
Keeping that in mind, that’s exactly why we designed Rookout to be a natural fit into the developer’s workflow. Well, also because we’re a tool that’s designed by developers, for developers. It may sound cliche, but it’s true. With an IDE-like user interface and a simple, one-time installation, we made sure that it’s very easy for developers to introduce Rookout into their debugging flow. And by integrating Rookout with popular observability and collaboration tools such as Jira, Slack, Datadog, and Elasticsearch, we ensure that the change to the way they work is minimal.
By making Rookout developer-friendly and easy to learn, and by ensuring that it saves them precious time with every debug session, we are also able to give them the feeling that tool was made for them, rather than a “mandatory” tool forced upon them by corporate.

The fallacy of Not Invented Here
A very common response of a software engineer (ourselves included!) to seeing a new dev tool is to challenge its developers and to believe that we could have developed it better ourselves. This response becomes more severe in cases where we’ve actually tried implementing something similar ourselves or if we think we have an alternative, tailored solution for a neighboring solution.
Accepting a commercial tool would mean that the local solution we built (or are planning to build) isn’t good enough and that we are not good enough as engineers.
Even worse – it would imply that the time and effort that we have already invested in developing it have been for nothing. Or that the engineers who have been dedicated to developing and maintaining the homegrown solution will now have no work to do.
As experienced R&D managers, we know the origins of this fallacy, which mixes “Not Invented Here” with a healthy portion of “Buy Versus Build” bias. We know that when applicable, paying for a specialized tool will free our engineers to work on the actual product. We know that a solution with an entire company behind it will have a much richer set of features and a more robust, secure and scalable architecture. And we know that the “sunken investment bias” is, as it is named – a bias.
Where live application debugging fits
Introducing live debugging, and specifically Rookout, into your development and debugging workflow will keep your team effective and satisfied. By allowing you to solve customer issues faster, it will help your company meet its business goals, and will free your developers to develop new features and provide more value to your customers.
Rookout was designed in a way that will integrate seamlessly with how your developers work today, and its ease of use and installation will make a build vs buy decision very easy to make. In conclusion, no matter which tool you use, Live Debugging is a necessity, not a bonus. And Rookout lets you implement live debugging quickly and easily, in a way that will keep your developers happy.
Related posts