Definitive Guide to Remote Java Debugging
In the world of software development, there’s no such thing as writing perfect code. As such, almost every software developer ends up spending a great deal of their time debugging code. Therefore, one of the best ways to increase your efficiency as a developer is to have the ability to locate errors, identify the root cause, and fix it to resolve problems in your codebase. While debugging is very crucial to producing high-quality software, it is also one of the most challenging skills to master.
As a developer, you can always improve your understanding of debugging by using new resources and taking a logical, rational, and analytical line of attack when confronting coding problems. Additionally, you must focus on learning and adopting the most helpful and effective debugging techniques. One such technique is remote debugging, which comes in handy when developing and maintaining software in today’s progressively remote-focused world.
In this article, we will explain everything you need to know about remote debugging using Java. Before diving into more details, let’s understand what exactly remote debugging means.
What is Remote Java Debugging?
Remote Java Debugging is the process of debugging a Java program or application running on another machine or a server environment. Unlike local debugging, where you debug an application that runs on the same device as your IDE, remote debugging requires establishing a connection between the debugger and the target system.
To demonstrate this a bit better, here’s a quick refresher of the Java Platform Debugger Architecture (JPDA) by Sun Microsystems. JPDA is a multi-tier architecture through which you can debug Java applications. It comprises the Java Debug Interface (JDI), the Java Virtual Machine Tool Interface (JVMTI), and the Java Debug Wire Protocol (JDWP), as shown in this high-level architecture diagram.
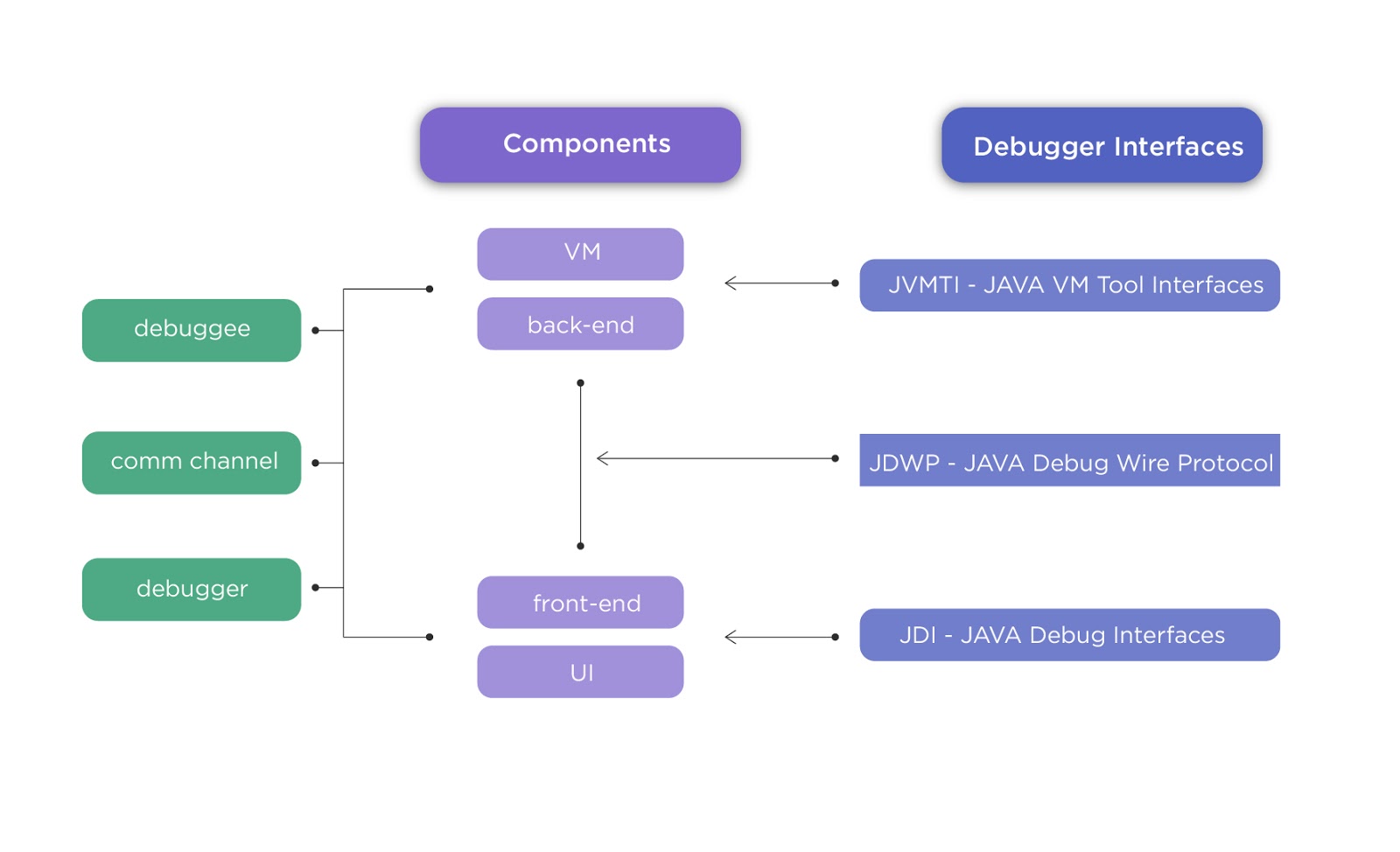
As illustrated, the Java Debug Wire Protocol (JDWP) is a protocol that contains information transmitted between the JVMTI and JDI. Once a connection is established, JDWP is used for communicating instructions between the debugger and debuggee (the application program being debugged) when performing remote debugging.
Remote Java debugging can be used to troubleshoot and fix the most common classes of bugs that Java developers run into time and again. These include:
- Run-time errors: these are errors that occur during program execution and usually throw exceptions.
- Logic errors: these bugs produce wrong or invalid outputs due to incorrect code implementation. However, they are different from run-time errors in that exceptions are not generated. Logic errors in Java can range from memory leaks to buffer overflow.
- Syntactical or compilation errors: these Java errors are highly common but easy to debug since they usually result from typing mistakes.
- Threading errors: this class of bugs constitutes the largest percentage of Java errors that every debugging tool should address. Threading bugs are usually difficult to reproduce and track down. They include deadlocks, synchronization errors, access violations, data race bugs, and more.
Why Use Remote Java Debugging
There are multiple reasons why developers may want to perform remote debugging. These include:
- When the target system cannot run a local debugger
It is common for developers to encounter situations where the target system does not support a local debugger. For instance, when debugging an embedded system where attaching a debugger is difficult, you might want to debug the application remotely. The same applies to distributed applications where logging is decentralized, and replicating a bug is more complicated.
Similarly, in the event that the target system lacks enough resources, for instance, memory or CPU power, to support the running applications and a resident debugger concurrently, you can only resort to remote debugging.
- When local debugging sessions interfere with other applications running on the target system
Far too often, initiating a local debugging session steps in the way of running applications. This is usually the case when the target system is interactive. Using a remote debugger that directs its output to a remote screen helps avoid this problem.
Remote debugging also comes in handy when debugging applications residing on dedicated machines such as web servers whose services cannot be shut down to allow local debugging.
- When you cannot access the application’s source files from the target system
When the source files for the application being debugged cannot be accessed locally, you should establish a secure connection with the host system and launch a remote debugging session. This is also the case when debugging a program that relies on live data. When the visibility of some types of bugs depends on the state of a running system, remote debugging is the best way to check into the bugs and understand how they occur. This happens often when debugging problems in a production environment.
Remote Java debugging can also be used in scenarios where the developer and target system reside in different physical locations. This results in significant time and cost savings.
As you can see, there are tons of reasons why development teams may opt to debug a Java application remotely. And the beauty in performing remote Java debugging is that it enhances collaboration among development teams and allows developers to troubleshoot code problems in modern software architecture.
How to Perform Remote Java Debugging
Various debugging platforms allow developers to debug their Java applications remotely. This includes regular IDEs that support remote debugging capabilities such as Eclipse, NetBeans, Visual Studio, and IntelliJ IDEA. So, start by choosing a Java JVM that fits into your workflow and supports remote debugging.
To debug your Java application remotely, you should follow two distinct steps. The first involves passing remote debugging arguments to JVM, and the second, configuring your IDE to allow remote debugging.
Passing remote debugging arguments to JVM
JDWP contains a wide array of command-line arguments used for debugging. Xdebug is used to enable debugging features such as remote debugging while Xrunjdwp specifies JDWP implementation and connectivity details in the target VM. In Java V5 and subsequent releases, you use -agentlib:jdwp instead of -Xdebug and -Xrunjdwp.
To invoke a remote Java application application, you should supply the right configurations for transport, server, address, and suspend arguments, as shown below.
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=127.0.0.1:8000
For Java 5 and earlier, we use the runjdwp arguments as shown below.
java -Xdebug
– Xrunjdwp_transport=dt_socket,server=y,suspend=n,address=8000
You can learn more about JVM arguments and debug settings by checking the JPDA documentation.
Configuring the IDE
After passing remote debugging arguments to your JVM, you now need to configure your development environment to allow remote launch. Of course, the configuration steps you take will depend on the Java debugging tool you’re using.
When entering the configuration details for launching a remote debugging session, always ensure that you provide the remote machine’s correct hostname or IP address. Once done with the configuration, then you’re set for remote debugging.
Challenges of Remote Java Debugging
There are a few downsides associated with remote Java debugging. These include:
- Security implications: when performing remote debugging, you open up specific ports to allow the debugger to access the server. This introduces a potential security risk to your system since bad actors who hit the server can also initiate debugging or perform malicious actions.
- Performance degradation: remote debugging mode affects an application’s or server’s performance because some JVM optimizations that provide significant performance boost are usually disabled.
- Logging concerns: some logging implementations used during debugging usually write log information to files within the application. Such solutions are not perfect because if an application crashes, there’s a chance that you might lose recent log messages. Another scenario is when log information is buried deep inside a directory that is difficult to access. Getting diagnostic information from such files can oftentimes be frustrating.
An Effective Approach to Remote Java Debugging
To debug Java applications properly, you must collect data to figure out precisely what is causing the bug. However, this can be problematic when debugging a Java application remotely and can often come with many performance caveats, as mentioned earlier.
A better remote debugging option would be using an advanced debugger like Rookout, which allows you to debug Java applications smoothly in both development and production environments. Rookout is a unique live production debugger that enables you to collect on-demand data from live code, accelerating the identification of root causes and bug resolution.
Using a tool like Rookout will streamline the remote Java debugging process in multiple ways, but these are three of the most notable ones.
Setting non-breaking breakpoints
The vast majority of Java bugs involve thread interactions. For this reason, an excellent Java debugging tool should be thread-centric to enable easier identification of bugs in multi-threaded Java applications. Unfortunately, regular IDE debuggers do not address this because, as you step through the code, you slow down the debugging process, which prevents the recreation of erroneous events.
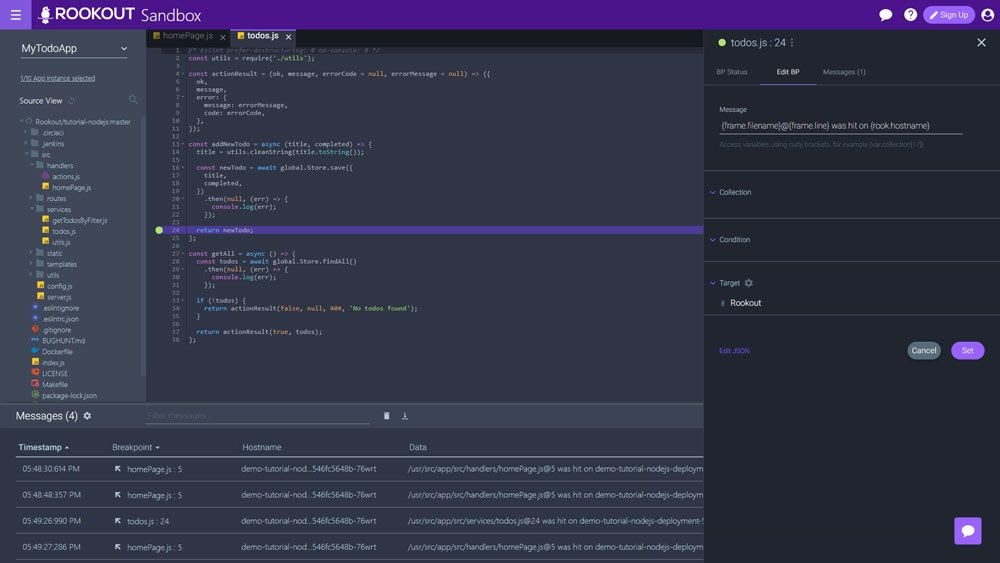
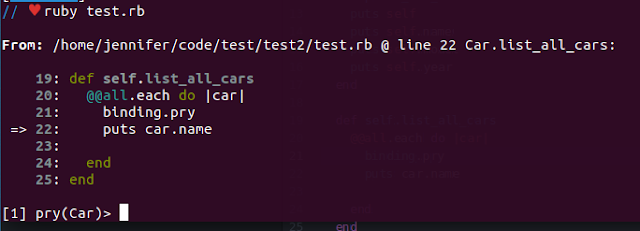
Using Rookout, you can remotely set and place non-breaking breakpoints in your Java application to inspect the full state or the live application or specific variables during execution. Non-breaking breakpoints help you identify and resolve common threading errors since they do not touch your code. This means you can get data from running code without breaking or stopping the application. This feature allows you to run remote Java debugging sessions as if you were debugging defective code locally using a classic debugger.
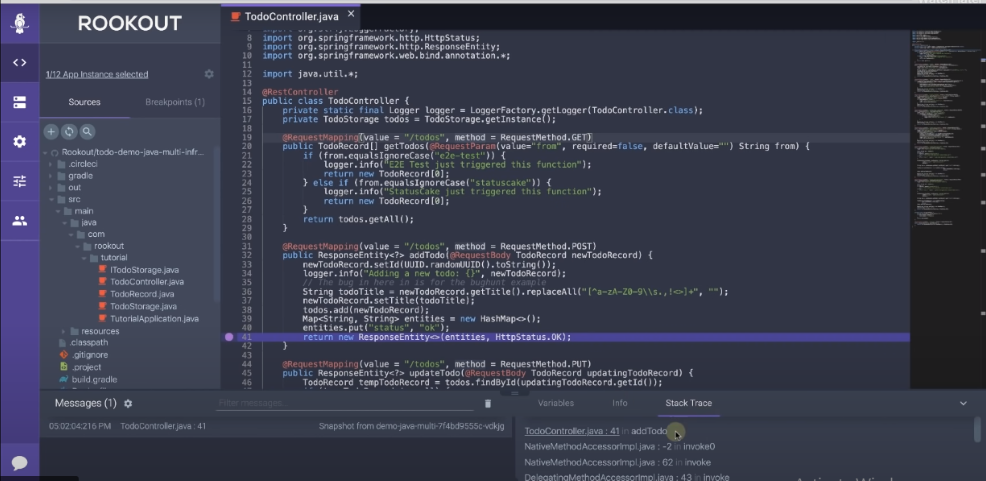
Here is a snapshot showing a non-breaking breakpoint set on line 41. Notice how you can inspect variables and their values, check the server, process information, and examine the stack trace on the Rookout debugger.
Seamless log-collection
Rookout streamlines log collection during debugging, thereby solving one of the most common pain points of remote debugging. This tool lets you extract live code data points, including logs, variables, and other metrics from your code without stopping your application, redeploying it, or writing extra code.
This allows instant observability into a running application, which speeds up root-cause analysis.
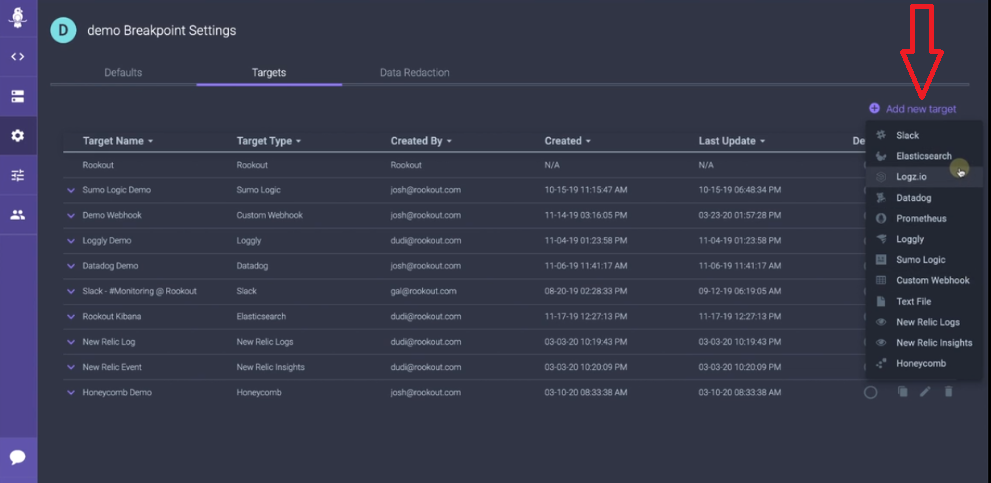
Besides fetching valuable data for debugging, Rookout allows you to export or pipeline your data to external performance monitoring, alerting, or logging solutions like Sentry or Datadog. You can see that the Rookout debugger allows you to export debugging data to a log analysis platform of your choice in the snapshot here.
Enhanced team effort
Another key benefit of using a solution like Rookout for remote debugging is that it enables developers to collaborate across support and engineering teams. Rookout focuses on conveying rich quality data containing details on software incidents and user behaviors. It also allows team members to share such detailed pictures for live debug sessions. This enhances team efforts since bug investigations are handed off with ease.
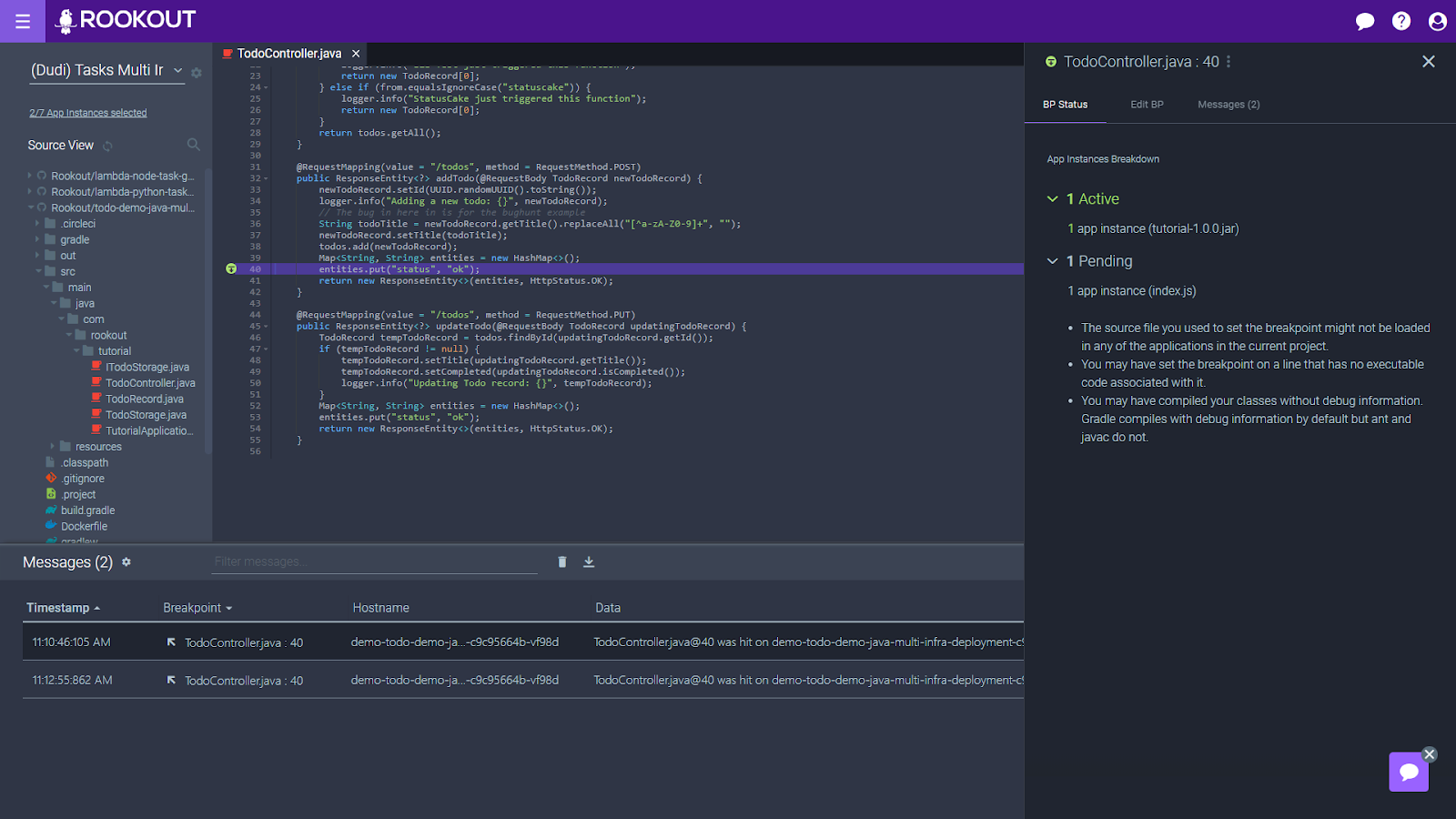
Here is a screenshot showing an example of a shareable debugging session in the Rookout debugger.
Tools like Rookout bring the much-needed agility to the modern debugging process. As remote working takes the world by storm, remote debugging becomes inevitable in our development workflow.
To facilitate smooth remote debugging, you should build an ideal Java debugging tool upon scale and distribution. This means that instead of having developers connect over a network every time they wish to debug an application, debugging platforms should provide greater control by allowing developers to debug an application component they want without struggling with debugger connections.
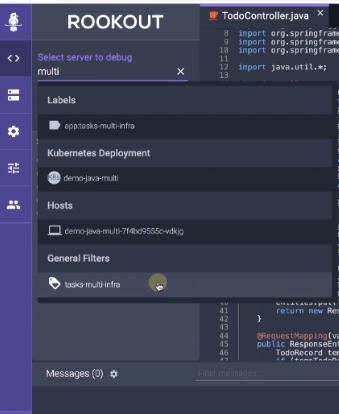
Rookout does precisely this. It saves users a lot of time spent on initial configuration for remote debugging. All you need to do is add a single line of code to your application’s entry file and any team member will be able to debug the application without additional configuration.
Best practices for Java Debugging
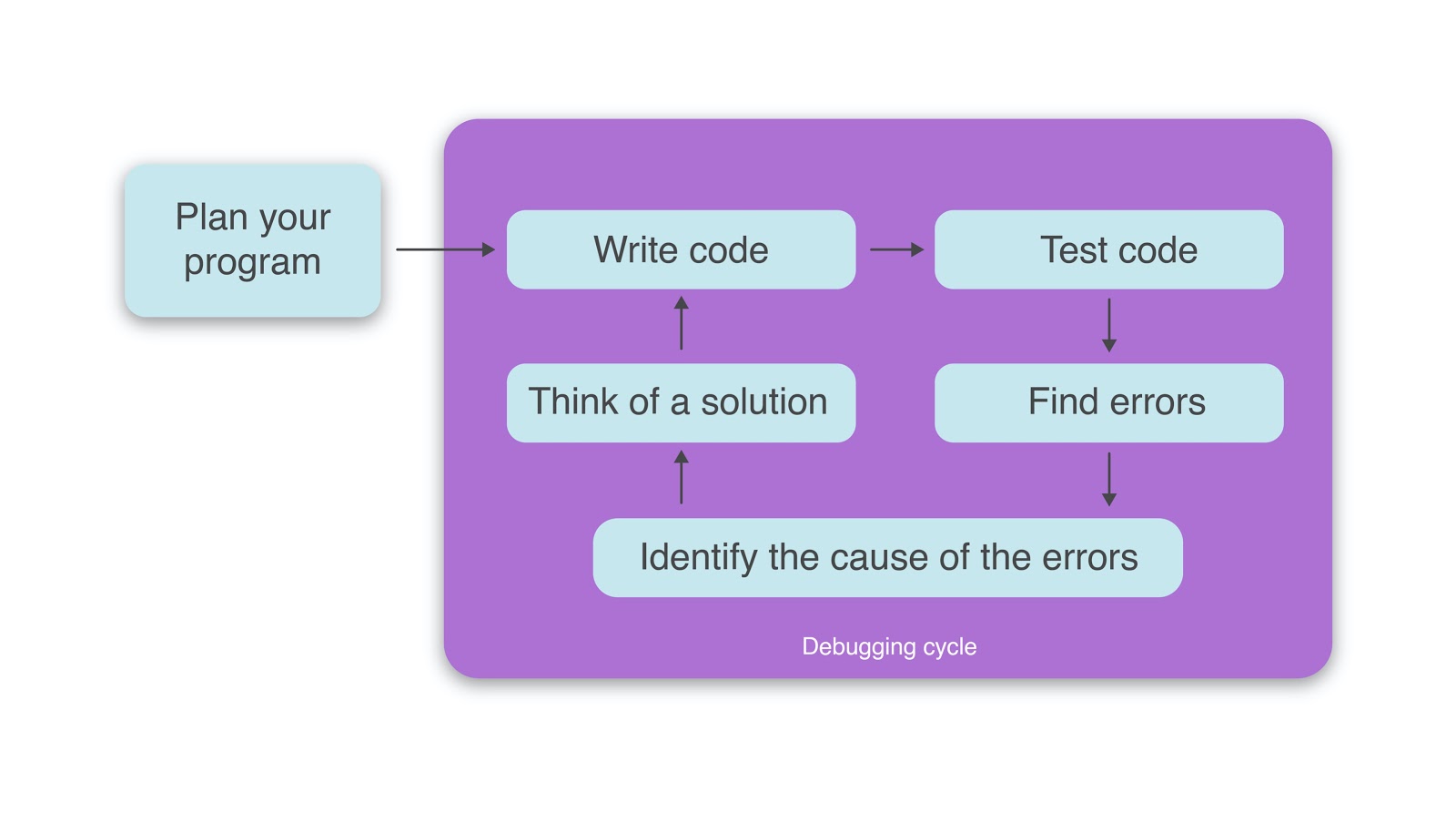
Debugging systems might seem challenging even to the most experienced coding veterans, especially when performing in a production environment. However, as a developer, you can make it easier by following the right techniques. Remember, the goal is to find the source of the problem in your Java code, determine possible causes, test out hypotheses until the actual root cause is found, and finally eliminate the causes to ensure it doesn’t happen again.
This process requires a systematic step-by-step approach, like the one shown below.
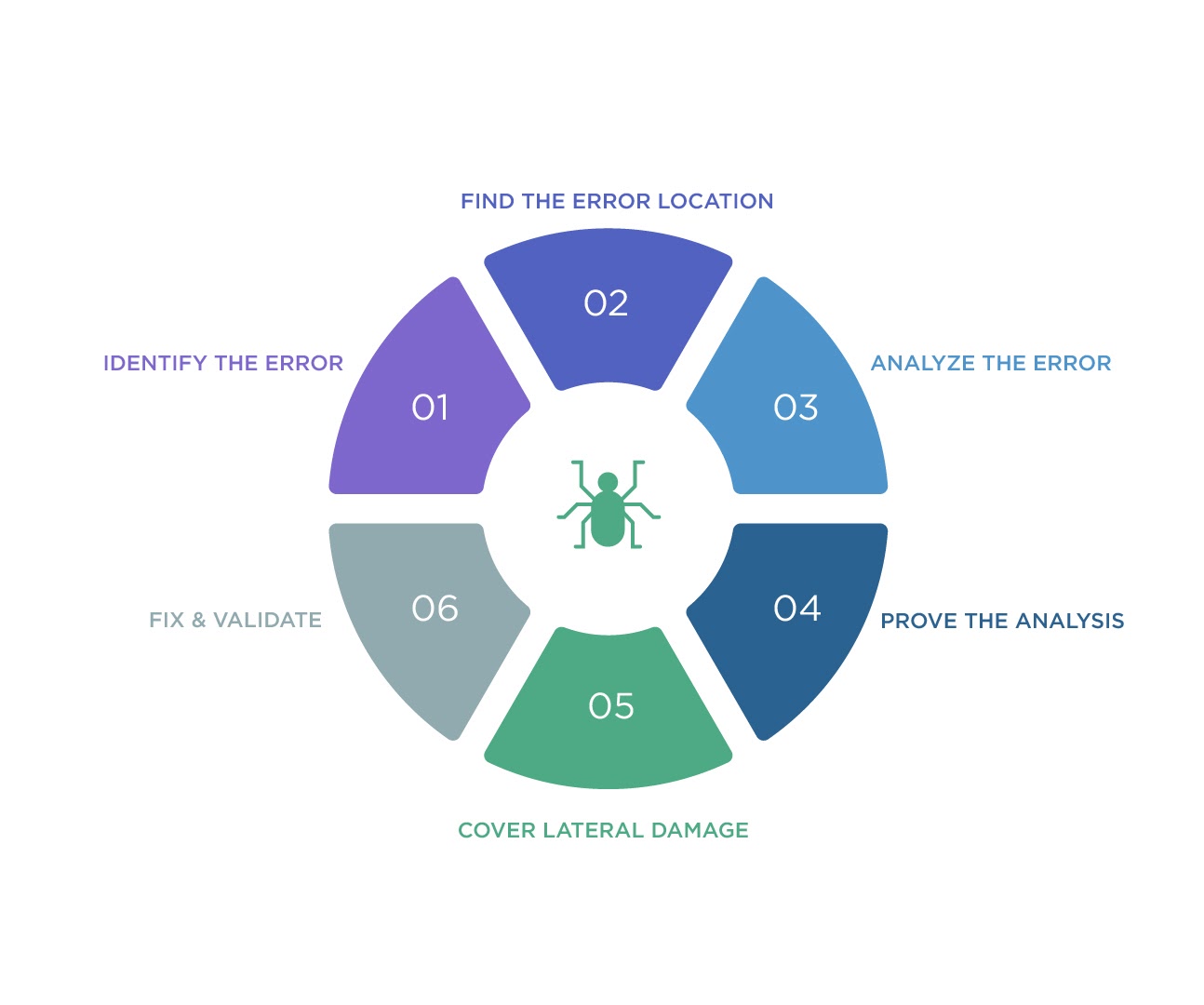
As a Java developer looking to excel in remote debugging, there are some fundamental rules that you should never neglect. This section puts together a couple of best practices essential for anyone looking to enhance their Java debugging skills and speed.
- First, refrain from using the debugger
There’s more to debugging than fiddling around the debugger and modifying your Java code to see if it works. So, the first rule of thumb when debugging a problem is to avoid firing up the debugger. We know the debugger can help solve virtually any problem in your codebase, but it’s not always the best place to start.
Instead, sit back and unleash the power of your mental arsenal to find the source of trouble in your codebase. When you understand how the system works, you will realize that tons of Java bugs can be fixed without touching the debugger.
- Reproduce the error
The easiest way to debug a problem is by recreating it. If you cannot understand the sequence of events leading to the problem, it will be almost impossible to solve it or verify that the applied fix works correctly. So, gather as much evidence as you can about the error, including all conditions leading to the problem.
If the bug in your Java code is an intermittent problem, do not claim that it cannot be replicated. Go ahead and insert a few more logging statements or non-breaking breakpoints in your code. The key is to gather as much information as possible about the problem.
After confirming that you can reproduce the problem, sit back and take a more in-depth look at the source code. See if you can get a few more clues about how the system should work. At this point, you should have a couple of hypotheses to test.
- Test your hypotheses
Most developers resort to opening the debugger to test their hypothesis. This is an okay route to take, but not just yet. A better approach would be creating unit tests that will exploit issues in parts of the program that aren’t working correctly.
Unit tests not only help you eliminate error possibilities in your debugging journey but also provide a way of verifying that your fix worked. Another advantage of writing unit tests is that even if they fail, you will have disproved your hypotheses and added another unit test to your system, thereby making it more robust.
In situations that you cannot write unit tests to exploit an error, then it’s okay to use the debugger. However, always be deliberate about what you want to debug and have a specific reason for doing it– not merely looking around your code.
- Validate assumptions
It is common for developers to make assumptions when debugging Java code. Instead of assuming that your code should be working in a particular manner or that the program should output certain values, stop and check if you’re on the right path.
By validating your expectations using unit tests, you will realize that every time you encounter an unexplainable bug, rarely will basic assumptions lie at the heart of the problem.
- Apply the divide and conquer method
One of the most effective ways of expediting the debugging process is cutting down the problem to narrow your search. When the system is split into two, it becomes easier to find the range of your target. Anytime you feel stuck, divide your Java codebase into two parts and eliminate that which cannot cause your problem.
Once you take away parts of your code that cannot be responsible for the error, you can work your way through the rest and identify those components behind the bug. When doing so, remember that some bugs defend each other. So, eliminate them as soon as you find them.
- Verify that the problem is really fixed
One last piece of advice when debugging Java code is that every time you fix a problem, always strive to understand why the fix worked. Remember, bugs do not go away by themselves, so if you can’t understand how the applied fix solves the intended problem, chances are that the bug might still be hiding.
We’re saying this because, during the course of your debugging journey, you tend to alter even the code that isn’t part of the official fix. While it is okay to have changes that do not break your code, some fixes might hide the problem. For this reason, you must always understand how your solution fixed the bug causes or erroneous compilation process. Additionally, you should consider running some regression tests to eliminate bug instances that might occur after the new build.
Conclusion
Whether you’re creating a new product or maintaining an already developed application, remote debugging comes in handy as a solution to the most prevalent debugging problems in modern software architecture. After all, bugs are an inevitable part of every programmer’s life. And like any other aspect of software development, remote debugging is an art and science that you can only excel at through constant learning and practice. So, use the tips in this article to guide you to streamline your remote Java debugging processes and remember to choose a tool that gives you the desired speed and ease in your development workflow.
References
- Java Debugging guide by Rookout
- The Java Platform Debugger Architecture (JPDA) documentation by Oracle
- Soft Skills: The Software Developer’s Life Manual by John Z. Sonmez
- Effective Debugging: 66 Specific Ways to Debug Software and Systems by Diomidis Spinellis
- Debugging: The 9 Indispensable Rules for Finding Even the Most Elusive Software and Hardware Problems by David J. Agans
Related posts




















![require 'rookout' ::Rookout.start token: ['[Your Rookout Token]', labels: {env: "dev"}]](/wp-content/uploads/2021/06/5fc8b11144aef2e74892118b_screen20shot202020-12-0320at2011.33.5720am.png)